Isolating Sources of Disentanglement in VAEs
VAEs中解纠缠源的分离
NeurIPS 2018

代码:https://github.com/rtqichen/beta-tcvae
摘要
我们分解证据的下界,以显示存在一项测量潜变量之间的总相关性。我们使用它来激发β-TCVAE(全相关变分自编码器)算法,这是β-VAE的改进和插件替换,用于学习解纠缠表示,在训练期间不需要额外的超参数。我们进一步提出了一种原则性的无分类器解纠缠度量方法,称为互信息间隙(MIG)。当使用我们的框架训练模型时,我们在受限和非受限环境中进行了大量定量和定性实验,并显示了总相关和解纠缠之间的强烈关系。
VAE
β-VAE:
VAE隐空间解耦:
- 解耦更接近人类的思维方式,人类也更加容易理解解耦的特征。我们在描述某人的外貌时,通常会说什么样的发型、身高多少、穿着如何等等。这些描述特征的因子共同表示了一个人的外貌。然而这些因子都耦合(隐藏)在图像的像素信息中。通过机器学习的办法,将这些因子解耦出来可以更好地反映出事物的本质特征
- 隐变量独立是解耦的必要条件
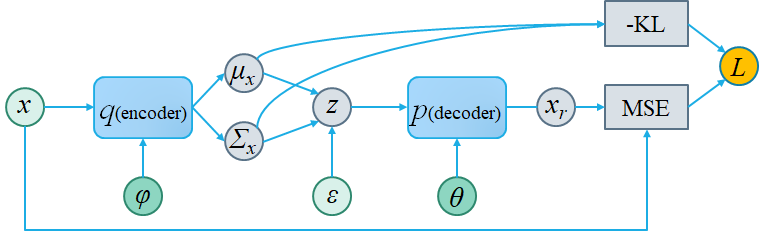

1 引言
在没有监督的情况下学习解纠缠的表示是一个困难的开放问题。解纠缠变量通常被认为包含可解释的语义信息,并反映数据中不同的变化因素。虽然解纠缠的定义还有待讨论,但许多人认为阶乘表示(具有统计上的自变量)是一个很好的起点[1,2,3]。这种表示将信息提炼成紧凑的形式,这种形式通常在语义上有意义,对各种任务都有用[2,4]。例如,对于对抗攻击[5],发现这样的表示更一般化和健壮。
许多最先进的学习解纠缠表示的方法都是基于现有目标的重加权部分。例如,潜变量与观测数据之间的互信息可以鼓励潜变量变得更可解释[6]。还认为,鼓励潜变量之间的独立性可诱导解纠缠[7]。然而,没有强有力的证据将阶乘表示与解纠缠联系起来。在某种程度上,这可以归因于薄弱的定性评价程序。虽然潜在表征中的遍历可以定性地说明解纠缠,但解纠缠的定量测量尚处于初级阶段。
在本文中,我们:
- 展示了一个变分下界的分解,可以用来解释β-VAE[7]在学习解纠缠表征方面的成功。
- 提出了一种基于加权小批的简单方法,在我们的分解项上使用任意权重进行随机训练,而不需要任何额外的超参数。
- 引入β-TCVAE,它可以作为β-VAE的插件替代,无需额外的超参数。经验评价表明,β-TCVAE比现有方法发现了更多可解释的表示,同时对随机初始化也相当稳健。
- 提出了一种新的信息论解纠缠的度量,该度量不受分类器限制,可推广到任意分布的非标量潜变量。
虽然Kim和Mnih[8]独立地提出了与β-TCVAE具有相同的总相关惩罚的增强VAE,但他们提出的训练方法与我们的不同,需要一个辅助鉴别器网络。
2 背景: 学习和评估解纠缠表征
我们讨论了现有的工作,目的是在没有监督的情况下学习解纠缠的表征或评估这些表征。这两个问题本质上是相关的,因为学习算法的改进需要对微妙细节敏感的评估指标,而更强的评估指标揭示了现有方法的不足。
2.1 学习解耦表示
VAE和β-VAE
变分自编码器(VAE)[9,10]是一种潜变量模型,它将自顶向下生成器与自底向上推理网络配对。训练不是直接对棘手的边际对数似然进行极大似然估计,而是通过优化可处理证据下界(ELBO)来完成。我们希望优化经验分布的均值下界(β = 1):
β-VAE[7]是变分自编码器的一个变体,它试图通过优化β > 1的严重惩罚目标来学习解纠缠表示。这种简单的惩罚已经被证明能够在图像数据集中获得高度解纠缠的模型。然而,没有明确说明为什么用阶乘先验惩罚 $\text{KL}(q(z|x)||p(z))$ 会导致学习潜变量对所有数据样本显示解纠缠变换。
InfoGAN
InfoGAN[6]是生成对抗网络(GAN)[11]的变体,通过最大化观测结果和潜变量子集之间的互信息,鼓励可解释的潜在表示。该方法依赖于优化难处理的互信息的下界。
2.2 评估解耦表示
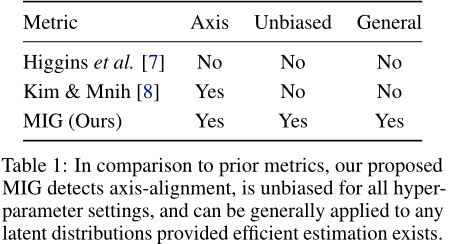
当真正的潜在生成因素被知道,并且我们有理由相信这组因素被解开时,就有可能创建一个有监督的评估指标。许多人提出了基于分类器的指标来评估解纠缠的质量[7,8,12,13,14,15]。我们将重点讨论[7]和[8]中提出的指标,因为它们在设计上相对简单且可推广。
Higgins’ metric[7]定义为低VC维线性分类器在识别固定的地面真值因子时所能达到的精度。具体来说,对于一组ground truth因子 $\set{vk}^K{k=1}$,每个训练数据点是L个样本的集合: $\frac{1}{L}\sum^L{l=1} |z^{(1)}_l −z^{(2)}_l |$,其中随机向量 $z^{(1)}_l,z^{(2)}_l$ 从 $q(z|v_k)^1$ 中i.i.d.提取 ($v_k$为固定值),分类目标k。该方法的缺点是缺乏轴对齐检测。也就是说,我们认为一个真正解耦的模型应该只包含一个与每个因素相关的潜变量。[8]建议使用 $\arg\min_j \text{Var}{q(z_j|v_k)}[z_j]$ 和多数投票分类器作为包含轴对齐检测的手段。
基于分类器的解纠缠度量往往是ad-hoc的,对超参数非常敏感。[7]和[8]中的度量可以粗略地解释为测量如果观测到v,z的熵约减量。在第4节中,我们证明了直接测量z和v之间的互信息是可能的,这是一个原则性的信息论量,可以用于任何潜在分布,只要有效估计存在。
(注意,$q(z|v_k)$ 通过使用中间数据样本进行抽样: $z∼q(z|x)$, $x∼p(x|v_k)$。)
5 相关工作
我们着重讨论以无监督的方式学习解纠缠的表示。尽管如此,我们注意到,通过薄弱的监督将已知的分离因素转化为生成过程已经被许多人所追求。在这种情况下,目标不是完美的反转,而是提取更简单的表示[15,25,26,27,28]。尽管没有明确的主要动机,但许多无监督生成建模框架已经探索了其学习表示的解纠缠[9,17,29]。在β-VAE[7]之前,一些已经在有限的环境中成功地进行了解纠缠,且变异因素很少[1,14,30,31]。
作为描述解纠缠表示的属性的一种手段,阶乘表示的动机有很多[1,2,3,22,32,33]。特别地,[22]的附录B显示了在具有灵活先验的相似目标中存在总相关,并假设最优性q(z) = p(z)。同样,[34]从一个结合了信息量和潜变量总相关性的目标中得到ELBO。相反,我们对未经修改的证据下界进行了更一般的分析。
[16]之前就已经证明了ELBO中指数码MI的存在,因此,使用与β-TCVAE相同目标的因子VAE被独立提出[8]。主要的区别是他们使用密度比技巧[35]估计总相关性,这需要一个辅助鉴别器网络和一个内部优化循环。相比之下,我们强调了β-VAE使用我们的精细化分解的成功,并提出了一种训练方法,允许为目标的每个项分配任意权重,而不需要任何额外的网络。
类似地,非线性独立成分分析[36,37,38]研究了假设独立潜在因素的生成过程的反演问题。而不是一个完美的倒置,我们只致力于最大化我们学习的表示和基本真理因子之间的相互信息。简单先验可以通过将复杂因素扭曲成更简单的流形来进一步鼓励可解释性。据我们所知,我们是第一个在阶乘表示和解纠缠之间显示强有力的可量化关系的人(见第6节)。
3 ELBO中解纠缠的来源
有人认为,在学习解纠缠表示时,有两个量特别重要[6,7]: A)潜变量和数据变量之间的互信息,B)潜变量之间的独立性。
用ELBO分解[16]说明了量化标准A的项。在本节中,我们将介绍一个细化的分解,显示ELBO中出现的描述这两个标准的术语。
ELBO TC-Decomposition
我们用一个唯一的整数索引来标识每个训练示例,并在{1,2, …, N}与数据点有关。进一步,我们定义 $q(z|n) = q(z|xn)$ 和 $q(z, n) = q(z|n)p(n) = q(z|n)\frac{1}{n}$。我们称 $q(z) = \sum^N{n=1} q(z| n)p(n)$ 为[17]后面的聚合后验,它捕捉了数据分布下潜变量的聚合结构。用这种表示法,我们分解(1)中的KL项,假设p(z)因式分解。
式中 $z_j$ 为潜变量的第j维数。
分解分析
- 在类似的分解[16]中,(i) 被称为索引码互信息(MI)。索引码MI是基于经验数据分布 $q(z,n)$ 的数据变量与潜变量之间的互信息 $I_q(z,n)$。有人认为互信息越高解纠缠越好[6],甚至有人提出在优化过程中完全取消对这一项的惩罚[17,18]。然而,最近对生成建模的研究也声称,通过信息瓶颈的惩罚互信息鼓励紧凑和解纠缠的表示[3,19]。
- 在信息论中,(ii) 被称为总相关(TC),它是对两个以上随机变量[20]的互信息的许多推广之一。这个命名是不幸的,因为它实际上是变量之间的依赖性的度量。对TC的惩罚迫使模型在数据分布中寻找统计上独立的因素。我们认为,对这一项的较重的惩罚可以诱导更清晰的表征,这一项的存在是β-VAE成功的原因。当 $q(z_j)$ 都独立时,此项为0,可以理解为最理想的解纠缠效果。
- 我们将 (iii) 称为维度上的KL,它主要防止每个潜维度与相应的先验偏差过大。
我们想通过只惩罚这个术语来验证TC是学习解纠缠表征的分解中最重要的术语这一说法;然而,在分解中很难估计这三个项。在下一节中,我们提出了一个简单而通用的框架,用于使用小批数据进行TC分解训练。
在[22]中给出了这种分解的一个特例,假设使用灵活先验可以有效地忽略维度上的KL项。相反,我们的分解(2)更普遍地适用于ELBO的许多应用。
3.1 小批量加权抽样训练
我们描述了一种随机估计分解项的方法,允许在每个分解项上使用任意权重进行可伸缩训练。注意,分解的表达式(2)需要计算密度 $q(z) = \mathbb{E}_{p(n)}[q(z|n)]$,这取决于整个数据集。因此,在训练过程中精确计算它是不可取的。【$q(z)$ 无法直接计算出来】我们的随机估计方法的一个主要优点是没有超参数或内部优化循环,这应该提供更稳定的训练。
基于来自 $p(n)$ 的小批样本的naïve蒙特卡洛近似很可能低估 $q(z)$。这可以直观地看出,将 $q(z)$ 视为一个混合分布,其中数据指标 $n$ 表示混合成分。对于一个随机抽样的成分,$q(z|n)$接近于0,而如果 $n$ 是 $z$ 的来源,$q(z|n)$ 会很大。因此,最好对该成分进行抽样,并适当地对概率进行加权。
为此,受重要性抽样的启发,我们建议在训练过程中使用一个加权版本来估计函数 $\log q(z)$。当提供一个小批次的样品 $\set{n_1,…, n_M}$,我们可以使用估计:(采样M个数据的估计方程)
其中 $z(n_i)$ 是来自 $q(z|n_i)$ 的样本(参见附录C中的推导)。
这个小批估计是有偏的,因为它的期望是一个下限(由Jensen不等式 $\mathbb{E}{p(n)}[\log q(z|n)]≤\log \mathbb{E}{p(n)}[q(z|n)]$ 得到)。然而,计算它不需要任何额外超参数。
3.1.1 特殊情况: β-TCVAE
使用小批量加权抽样,可以很容易地为(2)中的项分配不同的权重 (α, β, γ):
当我们用不同的 $α$ 和 $γ$ 值进行烧蚀实验时,我们最终发现调节 $β$ 可以得到最好的结果。我们提出的β-TCVAE使用 $α=γ=1$,只修改了超参数 $β$。Kim和Mnih[8]提出了一个等价的目标,他们使用辅助鉴别器网络来估计TC。
4 用互信息间隙测量解纠缠
没有适当的度量,很难比较解纠缠算法。大多数之前的工作都诉诸于通过可视化潜在表征的定性分析。另一种方法依赖于知道真正的生成过程 $p(n|v)$ 和ground truth潜在因素 $v$,这些通常是数据的语义意义属性。例如,摄影肖像通常包含分离的因素,如姿势(方位角和仰角)、照明条件和面部属性,如肤色、性别、脸宽等。虽然不能提供所有的ground truth因子,但仍然有可能使用已知因子来评估解纠缠。我们提出了一个基于潜变量和ground truth因子之间的经验互信息的度量。
4.1 互信息间隙 (Mutual Information Gap, MIG)
infoGAN中的互信息最大(MI max)是c和G(z,c)之间的互信息最大,使得生成器G过程中包含c的信息,infoGAN是无监督的。
本文中使用的互信息是z和真实factor之间的互信息,所以本文的方法是有监督的。
我们的关键思想是,可以使用联合分布 $q(zj, v_k) = \sum^N{n=1} p(v_k)p(n |v_k)q(z_j| n)$ 来估计潜变量 $z_j$ 和ground truth因子vk之间的经验互信息。假设基础因素 $p(v_k)$ 和生成过程是已知的经验数据样本 $p(n|v_k)$,则
其中 $\mathcal{X}_{v_k}$ 是 $p(n|v_k)$ 的支持。(参见附录b中的推导)
较高的互信息意味着 $z_j$ 包含大量关于 $v_k$ 的信息,如果 $z_j$ 和 $v_j$ 之间存在确定性的可逆关系,则互信息是最大的。此外,对于离散 $v_k$, $0≤I(z_j;v_k)≤H(v_k)$,其中 $H(v_k) = \mathbb{E}p(v_k)[−\log p(v_k)]$ 为 $v_k$ 的熵。因此,我们使用归一化互信息 $I(z_j;v_k) / H (v_k)$。
请注意,单个因素与多个潜变量可以具有高互信息。我们通过测量具有最高互信息的前两个潜变量之间的差来强制轴对齐。我们称之为互信息差(MIG)的完整度量是这样的:【一个因素 $v_k$可能与多个 $z_j$ 有很高的互信息,可是我们只希望有一个最大的互信息值,那么就使用下面的公式,每对互信息值减去第二大的互信息值,让其他的 $z$ 变小】
其中 $j(k) = \arg\max_j I_n(z_j;v_k)$, K是已知因子的个数。MIG的边界是0和1。我们执行整个数据集的传递来估计MIG。
虽然可以只计算平均的最大MI, $\frac{1}{K}\sum^K_{k=1} \frac{I_n(z_k *;v_k)}{H(v_k)}$,但我们的公式(6)中的差距防止了两个重要的情况。第一种情况与因子的旋转有关。当一组潜变量不是轴向对齐时,每个变量都可以包含关于两个或多个因素的大量信息。间隙严重影响未对齐的变量,这表明存在纠缠。第二种情况与表示的紧凑性有关。如果一个潜变量可靠地模拟了一个基本真理因子,那么其他潜变量就没有必要也提供关于该因子的信息。
如表1所示,我们的度量检测轴对齐,并且通常适用于任何分解的潜在分布,包括多模态、类别和其他结构化分布的向量。这是因为度量只受限于是否可以估计互信息。互信息的有效估计是一个正在进行的研究课题[23,24],但我们发现,对于我们使用的数据集,可以在合理的时间内计算出简单估计量(5)。我们发现,与现有指标相比,MIG可以更好地捕捉模型中的细微差异。分析MIG和现有指标的系统实验见附录G。
6 实验
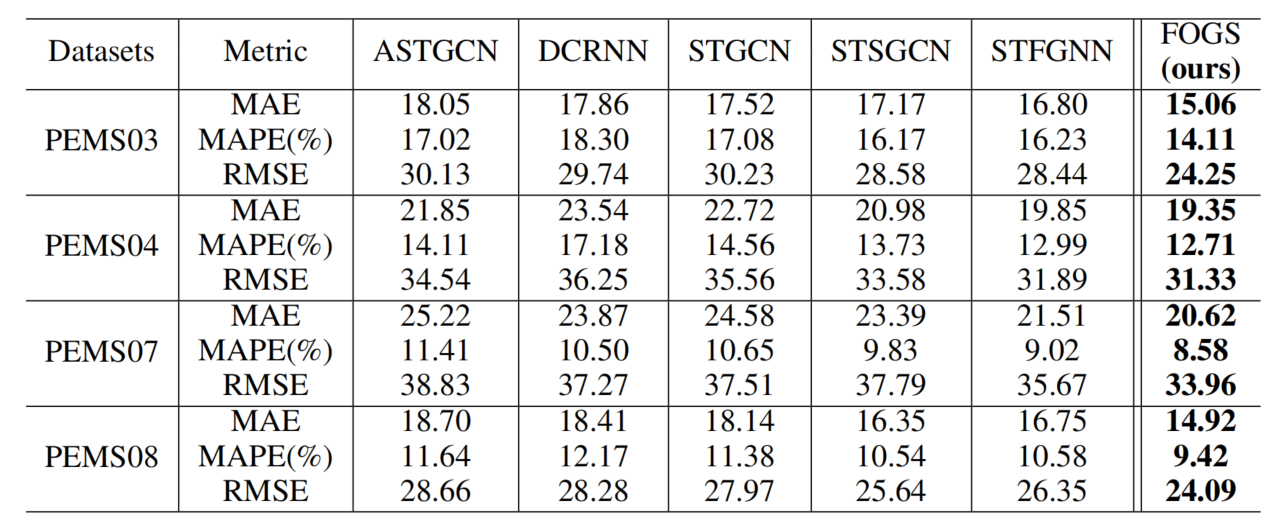
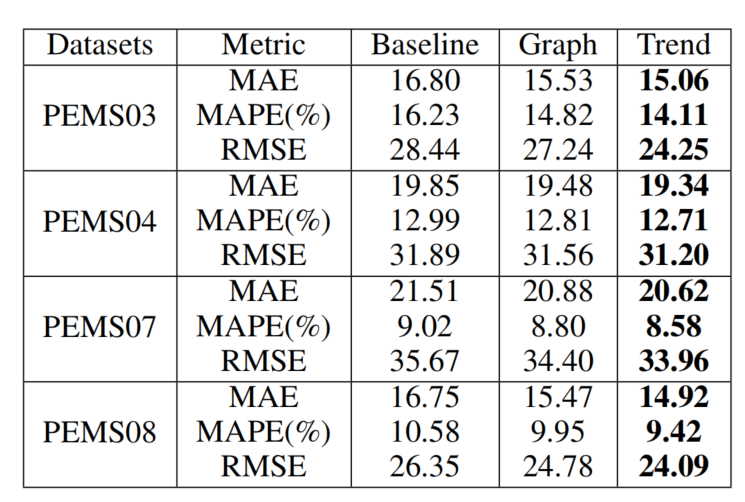
我们进行了一系列定量和定性实验,表明β-TCVAE与之前的β-VAE[7]和InfoGAN[6]方法相比,可以持续获得更高的MIG分数,并可以与FactorVAE[8]的性能相匹配,同时在密度比技巧难以训练的场景中表现更好。此外,我们发现在用我们的方法训练的模型中,总相关与解纠缠有很强的相关性。
独立变异因素
首先,我们分析了我们提出的β-TCVAE和MIG度量在限制设置下的性能,地面真相因子是统一和独立采样的。为了更清晰地描绘学习算法的鲁棒性,我们聚合了来自多个实验的结果,以可视化初始化的效果。
我们使用两个数据集进行定量评估,一个数据集是2D形状[39],一个数据集是合成3D面孔[40]。表2总结了它们的ground truth因子。dSprites和3D人脸也分别包含3种形状和50个身份,在评估时将其作为噪声处理。
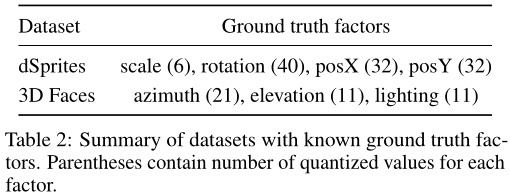
ELBO vs. 解纠缠权衡(β)
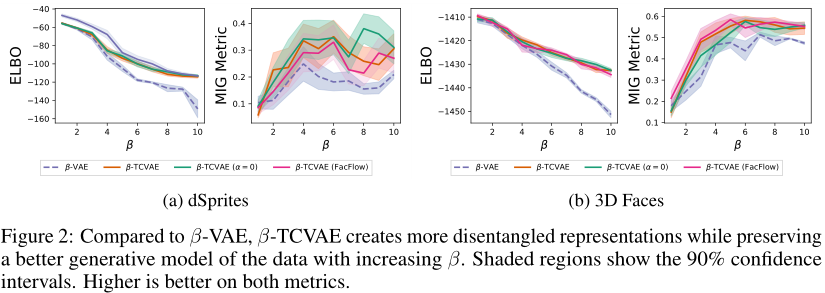
由于β-VAE和β-TCVAE目标是标准ELBO的下界,我们希望看到这种修改后的训练效果。为了了解β的选择如何影响这些学习算法,我们使用一系列值进行训练。密度估计和MIG测量的解纠缠量之间的权衡如图2所示。
我们发现β-TCVAE在密度估计和解纠缠之间提供了更好的权衡。值得注意的是,当β值较高时,β-VAE的互信息惩罚性太强,这阻碍了潜变量的有用性。然而,β-TCVAE与β-VAE相比,β-TCVAE具有更高的解纠缠分数。
我们还进行了消融研究,通过在(4)中设置α = 0来去除指数码MI项,并使用因式分解归一化流作为先验分布,联合训练以最大化修改目标的模型。这两种方法都没有带来显著的性能差异,这表明在(2)中调整TC项的权重对于学习解纠缠表示是最有用的。
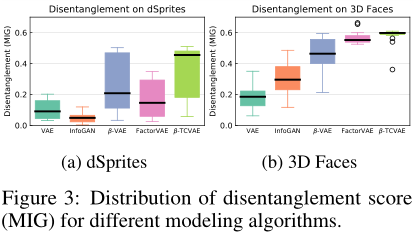
定量的比较
虽然一些学习算法可以实现解纠缠的表示,但获得这种表示的机会通常是不清楚的。解纠缠表示法的无监督学习可能具有很高的方差,因为在训练过程中没有提供解纠缠标签。为了进一步理解每种算法的鲁棒性,我们在图3中展示了描述各种方法的MIG评分分布的四分位数的箱形图。基于图2中的模态,我们使用β = 4表示β- VAE, β = 6表示β-TCVAE。对于InfoGAN,我们使用了5个连续潜码和5个噪声变量。根据[6]的建议选择其他设置,但我们还添加了实例噪声[41]来稳定训练。因子VAE使用与β-TCVAE相同的目标,但使用密度比技巧[35]进行训练,众所周知,这低估了TC项[8]。因此,我们调优了β∈[1,80],并对因子VAE使用了两倍的迭代次数。注意,β-VAE、factor-VAE和β-TCVAE对dSprites数据集使用全连接架构,而InfoGAN使用卷积架构提高稳定性。我们还发现,FactorVAE在完全连接的层上表现很差,结果比β-VAE在dSprites数据集上的结果更差。
总的来说,我们发现β-TCVAE的中位数得分最高,接近所有方法的最高得分。尽管在β-TCVAE测试中表现最好的一半人获得了相对较高的分数,我们看到另一半人仍然表现很差。低分离群值存在于3D人脸数据集中,尽管它们的分数仍然高于VAE和InfoGAN取得的中值分数。
阶乘与解纠缠表示
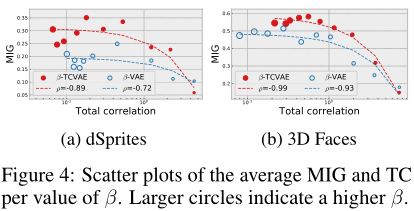
虽然先前已经推测低的总相关性会导致解纠缠,但我们提供了具体的证据,证明我们的β-TCVAE学习算法满足这一特性。图4显示了在dSprites和faces数据集上训练的不同β值的全相关散点图和MIG解纠缠度量,平均超过40个随机初始化。β-TCVAE训练模型的平均TC与平均MIG呈强负相关,而β-VAE训练模型的平均TC与平均MIG相关性较弱。总的来说,在相同的总相关度下,β-TCVAE建立了一个更好的解纠缠模型。这也为假设提供了有力的证据,即只要索引码互信息不受影响,大的β值是有用的。
6.1 相关或依赖因素
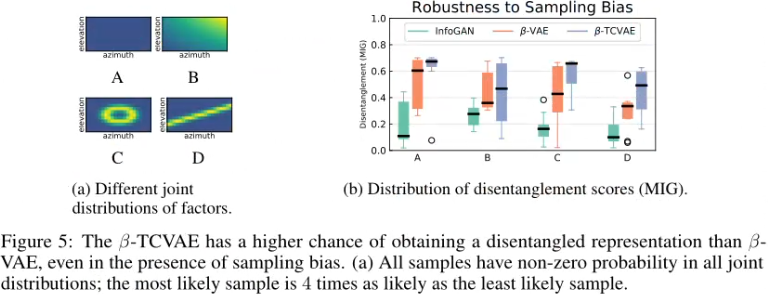
即使在底层生成过程对非均匀和依赖抽样的因素进行抽样时,也可以存在解纠缠的概念。许多真实的数据集都表现出这种行为,其中一些配置的因素比其他配置采样更多,违反了统计独立性假设。
在这种情况下,解开变异因素对应于找到生成模型,其中潜在因素可以独立作用并干扰生成结果,即使在抽样过程中存在偏差。总的来说,我们发现β-TCVAE在玩具数据集中找到正确的变异因子没有问题,而且可以找到比之前工作中发现的更多可解释的变异因子,即使违反了独立性假设。
Two Factors
我们从只有两个因素的玩具数据集开始,并使用具有不同程度相关性和依赖性的抽样分布测试β-TCVAE。我们取合成的三维人脸数据集,并固定除姿态外的所有因素。图5a总结了我们测试的因子的联合分布,其中包括不同程度的抽样偏差。具体来说,构型A使用了一致且独立的因子;B采用边缘不均匀但不相关且独立的因子;C使用了不相关但有依赖性的因素;D使用相关和依赖因素。虽然可以在所有配置中训练解纠缠模型,但当存在抽样偏差时,获得解纠缠模型的机会总体较低。在所有配置中,我们看到β-TCVAE优于β-VAE和InfoGAN,而且大多数配置的中位数得分存在很大差异。
6.1.1 定性的比较
我们定性地表明,β-TCVAE在椅子[42]和真实面孔[43]的数据集上发现了比β-VAE更多的分离因子。
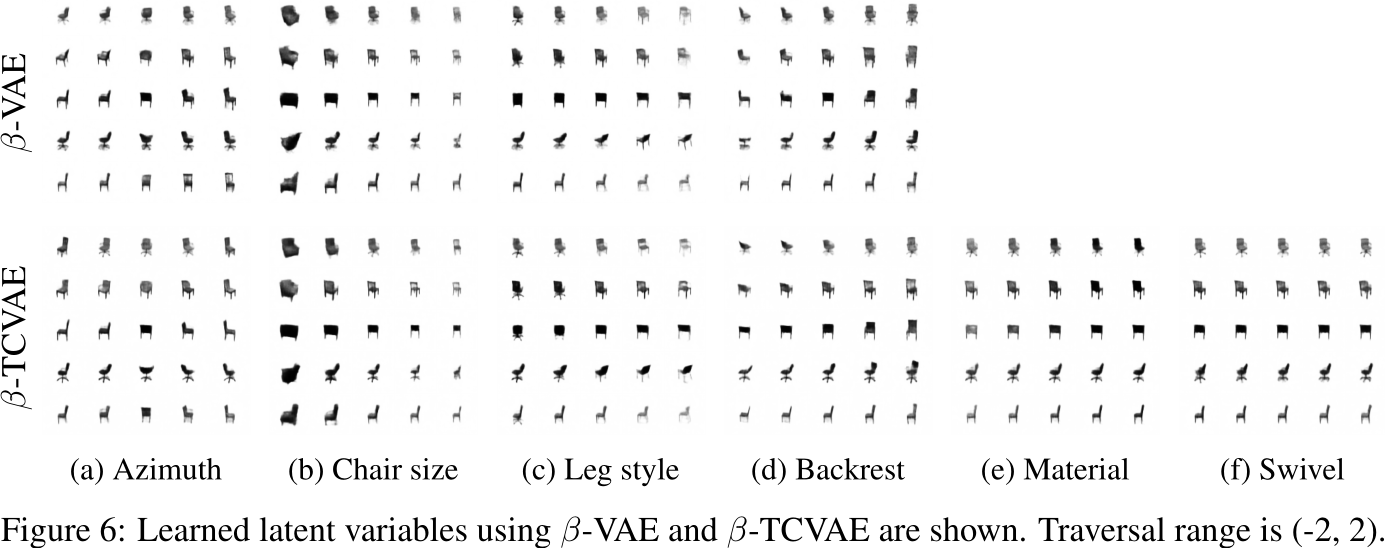
3D Chairs
图6显示了潜变量的遍历,描述了生成3D椅子的可解释属性。β-VAE[7]已经显示出能够学习前四种属性:方位、大小、腿型和靠背。然而,β-VAE学习到的腿型变化似乎并不适用于所有椅子。我们发现β-TCVAE可以学习另外两个可解释的特性:椅子的材料和旋转椅子的腿旋转。这两个性质更加微妙,可能需要更高的索引码互信息,因此β-TCVAE中较低的索引码互信息惩罚值有助于发现这些性质。
CelebA
图1显示了β-TCVAE在没有监督的情况下发现的15个属性中的4个(见附录A.3)。我们从平均值出发遍历6个标准差,以显示一般化每个变量的表示语义的效果。β-VAE学习到的表示是纠缠着细微差别的,这可以在推广到低概率区域时显示出来。例如,它很难呈现完全秃顶或窄脸宽度,而β-TCVAE显示有意义的外推。对β-TCVAE的性别属性外推表明,β-VAE更多地关注与性别相关的面部特征,而β-VAE则与许多不相关的因素如脸宽纠缠在一起。β-TCVAE模型的泛化能力超出了先验均值的前几个标准差,这意味着β-TCVAE模型可以生成罕见的样本,如秃头或有胡子的女性。

7 结论
我们提出了ELBO的分解,目的是解释β-VAE工作的原因。特别是,我们发现目标中的TC惩罚鼓励模型在数据分布中寻找统计上独立的因素。我们将β-TCVAE作为一种特殊情况,与β-VAE相比,它可以使用不附加超参数的小批估计进行随机训练。我们的方法的简单性允许很容易地集成到不同的框架[44]。为了定量评估我们的方法,我们提出了一种称为MIG的无分类器解纠缠度量。该度量得益于互信息[23]的高效计算的进步,并且除了解纠缠之外还加强了紧性。由于缺乏语义感知的先验,对解纠缠表示的无监督学习本质上是一个困难的问题,但我们在具有统一因子的简单数据集中表明,潜变量之间的独立性可能与解纠缠密切相关。
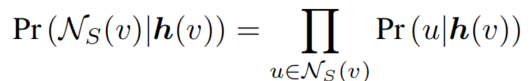
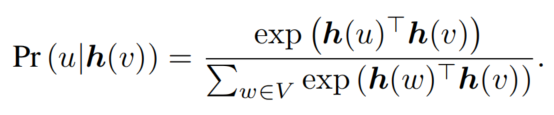
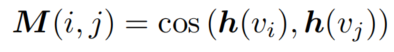
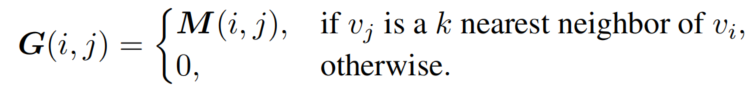
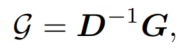
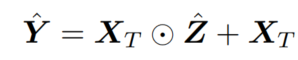



 是网络中间层的编码特征,我们表示
是网络中间层的编码特征,我们表示 和
和 分别为小批量中每个实例的通道特征均值和标准偏差,其公式如下:
分别为小批量中每个实例的通道特征均值和标准偏差,其公式如下:
 和
和 。具体而言,相应的高斯分布的中心被设置为每个特征的原始统计信息,而高斯分布的标准偏差描述了不同潜在位移的不确定性范围。通过使用概率方法随机抽样不同的合成特征统计,可以训练模型,以提高网络对统计变化的鲁棒性。
。具体而言,相应的高斯分布的中心被设置为每个特征的原始统计信息,而高斯分布的标准偏差描述了不同潜在位移的不确定性范围。通过使用概率方法随机抽样不同的合成特征统计,可以训练模型,以提高网络对统计变化的鲁棒性。
 与
与 分别表示特征平均值µ和特征标准偏差σ的不确定性估计。不确定性估计的大小可以揭示相应信道可能发生潜在变化的可能性。尽管域位移的潜在分布是不可预测的,但从小批量中捕获的不确定性估计可以为每个特征通道提供适当且有意义的变化范围,这不会损害模型训练,但可以模拟各种潜在位移。
分别表示特征平均值µ和特征标准偏差σ的不确定性估计。不确定性估计的大小可以揭示相应信道可能发生潜在变化的可能性。尽管域位移的潜在分布是不可预测的,但从小批量中捕获的不确定性估计可以为每个特征通道提供适当且有意义的变化范围,这不会损害模型训练,但可以模拟各种潜在位移。 和标准偏差
和标准偏差


 为可学习的参数,
为可学习的参数,







 得出的随机位移,均匀表示从
得出的随机位移,均匀表示从 ,其中∑是从我们的不确定性估计中获得的范围。如我们所见,直接使用具有不当变化范围的高斯分布将损害模型性能,这表明特征统计的变化范围应该有一些指导。
,其中∑是从我们的不确定性估计中获得的范围。如我们所见,直接使用具有不当变化范围的高斯分布将损害模型性能,这表明特征统计的变化范围应该有一些指导。




