信息
期刊: IJCNN
作者: 
摘要
传统的机器学习方法使用手工提取特征和精心设计的分类器,然而提取特征局限于我们的专业领域知识。
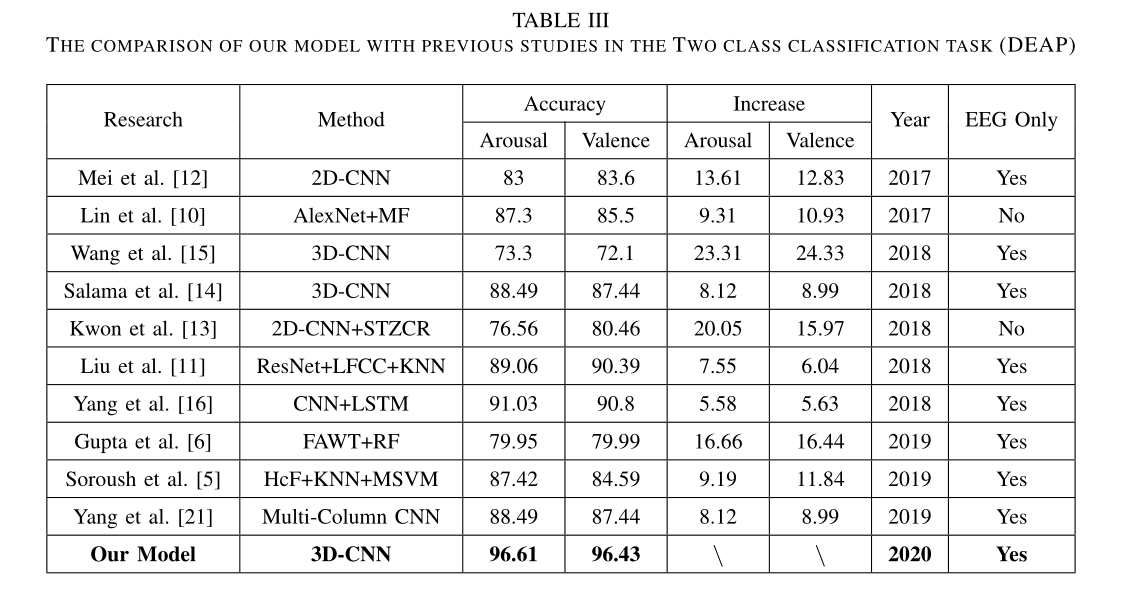
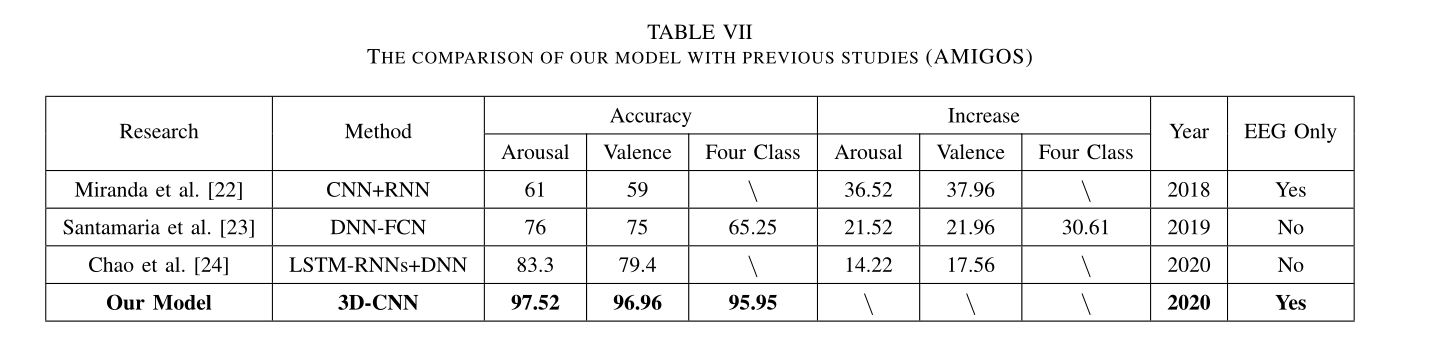
我们提出了一种三维卷积神经网络模型来自动提取脑电信号的时空特征,通过预处理信号和对电极拓扑结构的重定位,在DEAP数据集二分类任务上实现了96.61%、96.43%的ACC,四分类上实现了93.53%的ACC,在AMIGOS实现了97.52%、96.96%和95.86%ACC。
关键词
Emotion Recognition, Electroencephalography(EEG), 3D Convolutional Neural Network (3D CNN), Spatiotemporal Features, Deep Learning
介绍及相关工作
基于生理信号尤其是脑电图信号的识别方法已经成为研究热点,因为与面部表情或语音等其他信号相比,这些信号能够表征人的内在情绪状态,无法进行主观控制。
传统的机器学习方法提取特征主要有
- 时域特征。事件相关电位ERP,信号统计(功率,均值,标准差,一阶差分,二阶差分),高阶统计量(HOC)。
- 频域特征。功率谱密度(PSD),高阶谱(HOS)。
- 时频特征。希尔伯特黄谱(HHS),幅度平方相关估计(MSCE)。
深度学习方法中,2D卷积常规方法忽略了脑电信号的空间特征,因此提出了时空特征提取方法。
数据集
DEAP
DEAP是一个开放的数据集,供研究人员验证他们的模型。该数据集包含32个通道的脑电信号和8个通道的其余生理信号,这些信号是在32名参与者观看40个视频(每个视频时长1分钟)时采集的。每次试验包含63s信号,前3s是baseline信号。当参与者没有受到刺激时,记录baseline信号。看完一分钟的视频后,参与者对valence、arousal、liking和dominance自我评估进行评分,评分范围从1到9。
已经提供了预处理版本:数据从512赫兹下采样到128赫兹,并且应用了4.0-45.0赫兹的带通频率滤波器。DEAP的脑电数据大小为32(participants)x40(videos)x32(channels)x8064(signals),8064信号包含384个baseline信号。
AMIGOS
AMIGOS 是一个新开放的数据集。该数据集包含14导脑电信号和3导其余生理信号,采集于40名参与者观看20个视频(16个短视频 + 4个长视频)。每次试验首先包含5s的baseline信号,其他信号的长度取决于视频的持续时间。观看视频后,参与者还对valence、arousal、liking和dominance进行了1到9级的自我评估。
已经提供了预处理版本:数据被下采样到128赫兹,并应用了4.0-45.0赫兹的带通频率滤波器。
研究过程
预处理
Yang报告说,在情绪识别任务中,预处理方法可以将识别准确率提高大约32%。
预处理方法包括:
- 从所有通道C中提取baseline信号,并将其切割成固定长度L的N段,得到N段C×L矩阵
- 用分段数据计算baseline信号的均值,得到baseline信号均值矩阵
- 去除baseline信号,并且减去均值后进行切割,得到预处理后的信号。
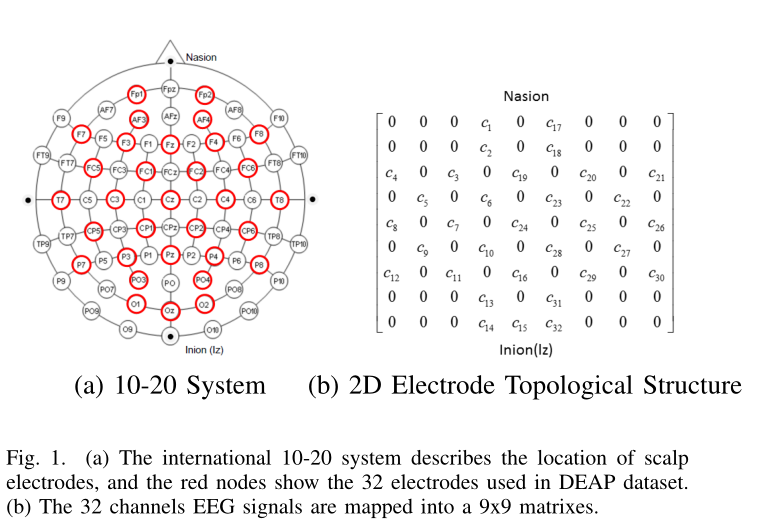 因为我们要利用空间位置,所以我们自己做了一个图。把32导转换到9*9的矩阵中去。我们转换的时候使用了标准化。
因为我们要利用空间位置,所以我们自己做了一个图。把32导转换到9*9的矩阵中去。我们转换的时候使用了标准化。
3D卷积结构
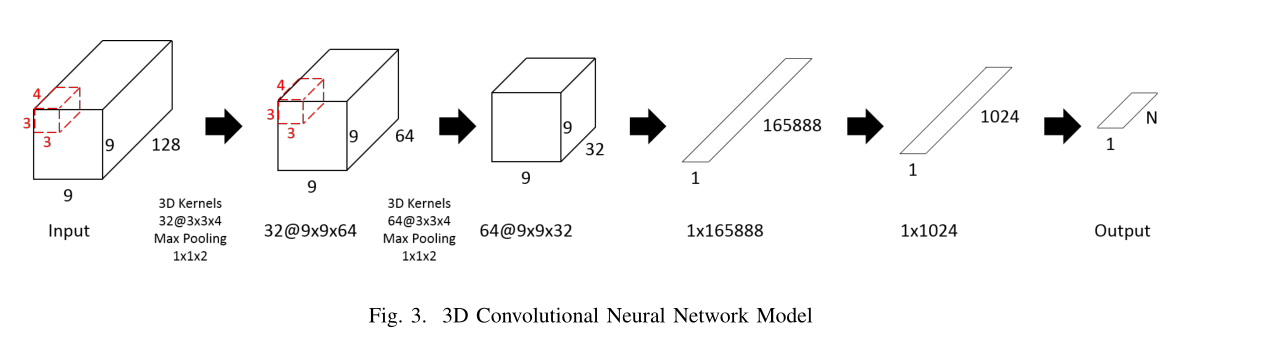
卷积结构如上,只有两个卷积层,每次卷积层跟着池化。
输入为(9,9,128)。前两维是空间位置图,最后一维是时间采样点的数量,也就是Hz。
卷积核的数量为32和64,大小为(3,3,4),卷积使用零填充,激活函数是relu。
池化层为(1,1,2)。
全连接层后跟着dropout,为0.5。
学习率为0.001。
batchsize为240。
验证方法是十倍交叉验证。
实验结果
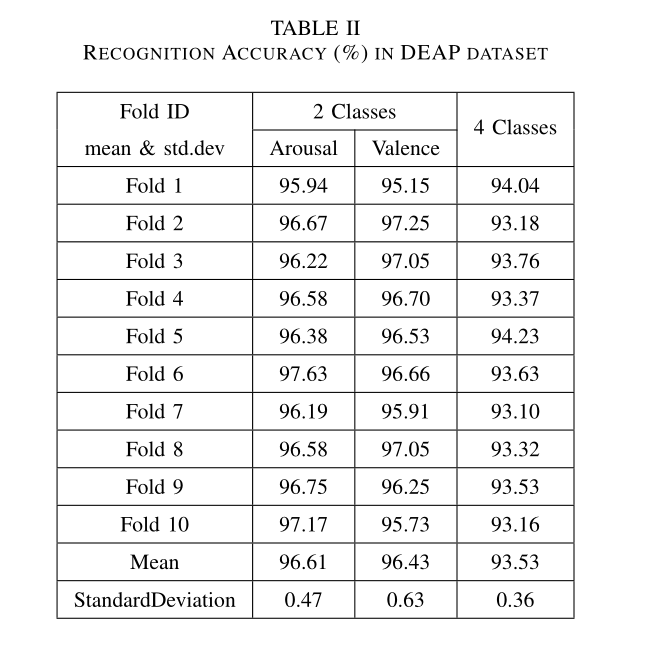
DEAP数据集结果
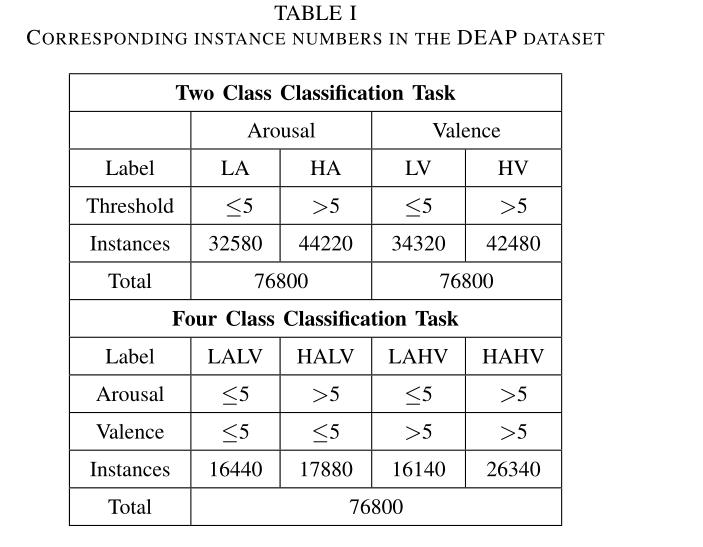
一次实验数据是(32×8064),把baseline信号(32×384)切割成3段(3×32×128),因为长3s,得到均值(1×32×128)。
将没有baseline信号的脑电信号分割成60段(60×32×128),然后减去baseline信号的均值,得到预处理后的信号(60×32×128)。
对于每个时间采样点,将32路脑电信号映射成一个9x9矩阵。最终数据集是(76800×9×9×128)。76800是32个人看40个视频,每个视频1分钟。
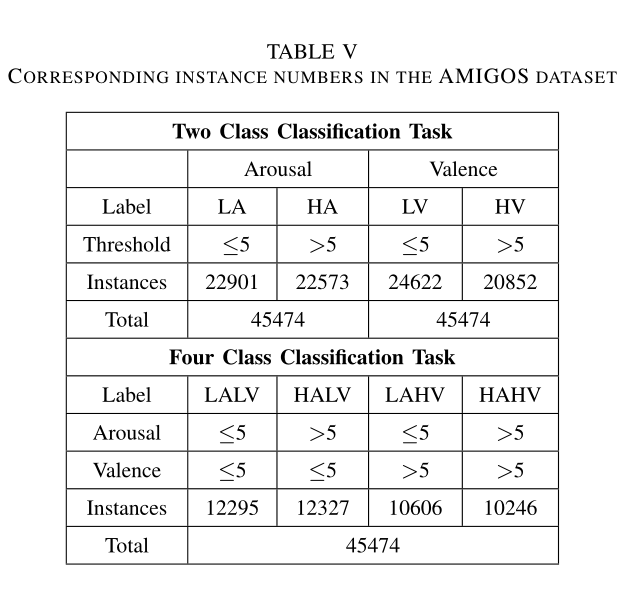
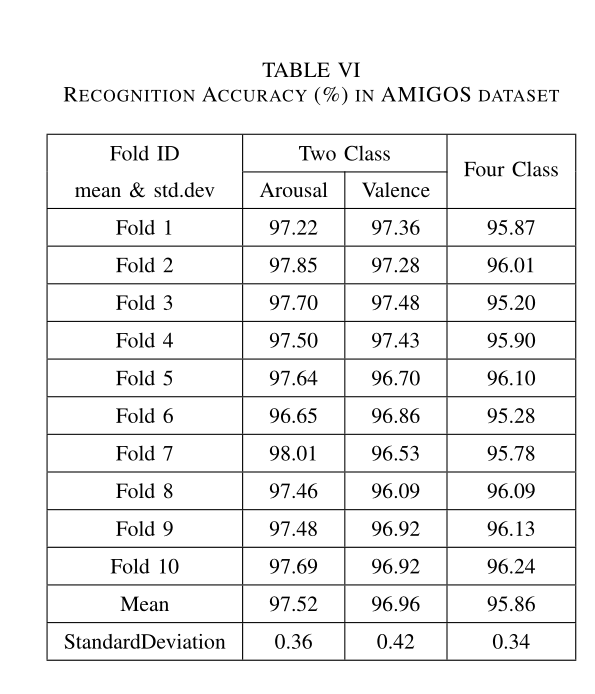
AMIGOS数据集结果
同上,最终有45474个样本。
结论
本文提出了一种简单有效的基于脑电信号的三维卷积神经网络模型,该模型可用于不同的任务和数据集。
缺点是,相比之下,深度学习方法往往被视为一个黑箱系统,我们将努力改进模型的可解释性,找出情感识别中的重要因素。