摘要
许多睡眠研究都面临数据不足的问题,无法充分利用深层神经网络,因为不同的实验室使用不同的记录设置,因此需要在相当小的数据库上训练算法,然而,由于通道不匹配,大型的数据库不能直接进行数据补偿。本文提出了一种深度转移学习方法来克服通道不匹配问题,并将知识从一个大的数据集转移到一个小的队列中来研究单通道输入下的自动睡眠分期。我们采用最先进的SeqSleepNet并在源域(即大数据集)中训练网络。然后,在目标域(即小群体)中对预训练网络进行微调,完成知识转移。我们研究了源域和目标域之间存在轻微和严重通道不匹配的两种迁移学习场景。我们还研究微调完全或部分预训练的网络是否会影响目标域上睡眠分段的性能。
本研究以蒙特利尔睡眠研究档案馆(MASS)的200名受试者为源域,以20名受试者组成的Sleep-EDF扩展数据库作为目标域,我们的实验结果表明,所提出的深度转移学习方法在睡眠分期方面有显著的改善。此外,这些结果也揭示了微调预训练网络的特征学习部分以绕过信道失配问题的必要性。
文献信息
会议: 2019 27th European Signal Processing Conference (EUSIPCO)
作者:
Huy Phan , Oliver Y. Chen, Philipp Koch, Alfred Mertins, and Maarten De Vos
University of Kent, United Kingdom
University of Oxford, United Kingdom
关键词
Automatic sleep staging, deep learning, transfer learning, SeqSleepNet
背景介绍
深度学习的缺陷
深度学习已经成功地应用于许多领域,并受到睡眠研究界的广泛关注。深度学习具有自动表示学习理解大数据集的能力,显著提高了自动睡眠分期的性能,准确率达到睡眠专家手动评分的水平。
然而,这种专家水平的表现只有在研究群体规模较大时才能获得,即数百到数千名受试者。原因是深层神经网络通常需要大量的数据来训练。在实践中,许多睡眠研究都有一个小群体,比如几十个研究对象,有时甚至更少,尤其是那些与睡眠障碍相关的研究或探索新的通道位置。
当不同的研究使用不同的通道布局或可能探索新的电极放置时,会出现通道失配问题。此外,当研究调查一种特殊的睡眠异常时,这种情况也会发生,当模型只在健康志愿者身上进行训练时,可能会获得较差的表现。
我们的工作
我们提出了一种转移学习的方法来解决信道失配问题,使得从一个大数据库中有效地转移知识,从而在更小的数据集中利用深度神经网络来研究单通道睡眠分期。
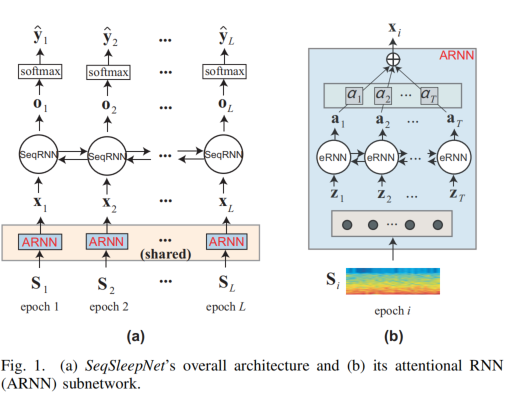
本研究以蒙特利尔睡眠研究档案馆(MASS)数据库为源域,以20名受试者为目标域的Sleep-EDF扩展数据库。SeqSleepNet是一种序列到序列的模型,它被用作基本模型。
首先用源域数据训练网络,然后用目标域数据对网络进行微调。研究了两种情况:(1)源域为EEG信道,目标域为另一个EEG信道时,信道轻微不匹配的同态转移学习;(2)源域为EEG信道,目标域为EOG信道时,信道严重不匹配的跨模态转移学习。此外,我们研究了不同的微调策略,以深入了解不同通道失配条件下的深度转移学习。
数据集
本研究以MASS为源域。这个数据集包括200名年龄在18至76岁之间的受试者的整晚记录(97名男性和103名女性)。睡眠专家根据AASM标准(SS1和SS3子集)或R&K标准(SS2、SS4和SS5子集)对记录的每个时期进行手动注释。
我们转化为W,N1,N2,N3,REM。将20秒的epoch扩展为30秒的epoch。我们采用C4-A1脑电通道(C4-A1)作为源域数据。最初采样频率为256Hz的信号被降采样至100Hz。

我们采用SLEEP-EDF数据集中的(SC)子集作为目标域。它由20名年龄在25-34岁之间的受试者组成。采样频率为100Hz,每个受试者都可以获得随后两个白天和夜晚的PSG记录,只有一个受试者(受试者13)是一个晚上的数据。睡眠专家根据R&K标准对每30秒的记录进行手动标记,分为八类{W,N1,N2,N3,N4,REM,MOVEMENT,UNKNOWN}。与之前的工作相似,N3和N4级合并为单个N3级。排除运动和未知类别。在同一通道和跨通道转移学习实验中,我们研究了Fpz-Cz-EEG通道和EOG通道。根据以前论文的建议,只包括了录音的床上部分(从熄灯时间到开灯时间)。
本文方法
模型结构
图卷积
损失函数
Xs和Xt是源域和目标域提取的特征是由以下过程得到,X为CNN提取的样本特征,我们认为这是图信号,即图中每个节点的特征。图的邻接矩阵由DSA网络提取Xsc,然后乘以其转置矩阵得到邻接矩阵A。这样我们就有了A和X,可以进行图卷积。
分类损失
交叉熵损失
域对齐损失
structure-aware 对齐损失
利用triplet loss来约束DSA结构。
由于CNN的源特征和目标特征在训练初期具有区域区分性,同时构造图可能会影响网络训练的稳定性。因此,源图和目标图被单独构造并输入到参数共享的gcn中以学习表示。
类质心对齐损失
距离度量函数选择的是欧氏距离。
实验结果
数据集
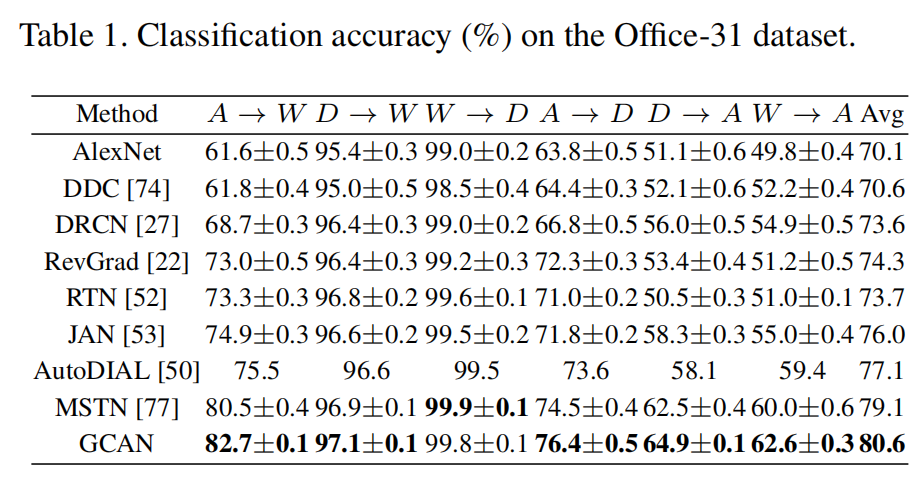
Office-31 来自三个不同域的31个类中的4110个图像,三个域分别是亚马逊A、网络摄像头W和单反相机D。
ImageCrep-DA 是ImageCrep 2014域适应挑战赛的基准数据集,它包含以下三个公共数据集12个常见类别。每个数据集被视为一个域:Caltrch-256(C)、ImageNet ILSVRC 2012(I)和Pascal VOC 2012(P)。每个类别有50个图像,每个域有600个图像。
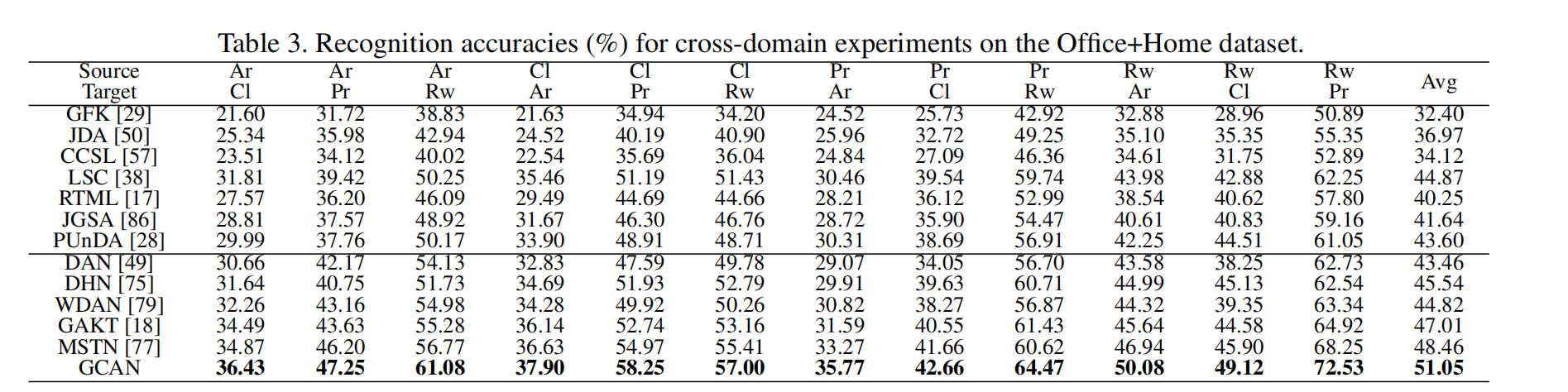
Office Home 包含4个域,每个域有65个类别,都是日常用品。具体而言,Art(Ar)是对象图像的艺术描绘,Clipart(Cl)表示剪贴画的图片集合,Product(Pr)显示背景清晰的物品图像。
实验设置
我们使用0.9动量的随机梯度下降,学习速率按µp=µ0*(1+α·p)^β退火,其中µ0=0.01,α=10,β=0.75。我们将微调层的学习速率设置为学习率的0.1倍。
我们将每个域的batchs size设置为128。域对抗性系数损失0.1。
Office-31
ImageCLEF-DA

Office-home
结论
在本文中,我们提出了一种新的方法,在统一的深层网络中联合使用数据结构、域标签和类标签信息,以实现无监督域自适应。
为了实现源域和目标域分布的鲁棒匹配,我们设计了三种有效的对齐机制,包括结构感知对齐、域对齐和类质心对齐。
这三种对齐机制可以相互增强和互补,以学习目标任务的领域不变性和区分性表示。在标准域自适应数据集上的实验验证了该模型的有效性。