Improving EEG-Based Emotion Classification Using Conditional Transfer Learning
[TOC]
信息
期刊: Frontiers in Human Neuroscience, 2017
作者: Yuan-Pin Lin, National Sun Yat-sen University; Tzyy-Ping Jung, University of California, San Diego
摘要
近年来,迁移学习在脑电信号挖掘领域受到越来越多的关注。然而,盲目的迁移学习也会导致负迁移现象。
本研究提出了一个条件迁移(cTL)框架,以促进每个个体的正迁移。通过对26的个体进行实验,相比仅仅利用自身的数据,在valence分类上提升了15%,在arousal分类上提升了26%。
简单来讲,cTL设置了一个阈值,如果准确率不高,则可以考虑迁移学习(利用其他相似个体的数据),否则没必要进行迁移学习。
关键词
EEG,emotion,transfer learning,classification
介绍
现状: 为个体开发一个适应的模型效果应该是比较好的,但是因为缺乏数据,已经成为一个瓶颈问题。
一个直接的方案是基于受试者群体的数据开发一个独立于受试者的分类模型,而不是为每个个体构建一个依赖于受试者的模型。如果个体之间的类分布在某种程度上是相似的,那应该有不错的效果。但是实际情况往往不满足这些情况,所以广义的分类器有时无法取得优秀的结果。
Zhu J , Zheng W , Lu B . Cross-subject and Cross-gender Emotion Classification from EEG[J]. 2015.
另一个方案允许个体选择性地使模型适应来自其他受试者的数据或信息,从而可以在某种程度上减轻个体差异的影响。
TCA: Zheng W L , Zhang Y Q , Zhu J Y , et al. Transfer components between subjects for EEG-based emotion recognition[C]// International Conference on Affective Computing & Intelligent Interaction. IEEE, 2015.
KPCA: Zheng W L, Lu B L. Personalizing EEG-based affective models with transfer learning[C]//Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. 2016: 2732-2738.
TPT: Sangineto E, Zen G, Ricci E, et al. We are not all equal: Personalizing models for facial expression analysis with transductive parameter transfer[C]//Proceedings of the 22nd ACM international conference on Multimedia. 2014: 357-366.
研究过程
假设(通过实验验证)
- 本研究假设TL框架可以显著改善那些参与度低的受试者的分类器。
- 本研究进一步假设由TL获得的分类性能的提高应该与目标域和源域中包含的受试者的相似程度正相关。
数据集
Oscar soundtrack EEG dataset ,数据集由从26名健康受试者收集的30通道脑电图信号组成。音乐使用了16个30s音乐节选,并试图按照二维valence-arousal情绪模型归纳出四种情绪类别。
本文中因为类别分类不平衡,将四分类问题改为两个二分类问题。
处理EEG信号
- 通过短时傅里叶变换+50%覆盖的汉明窗,通过1-50Hz的巴特沃斯滤波器获得了五个频带。
- 通过DLAT对12导的五个频带进行处理,生成了60维特征,然后除以前5s的平均能量值,使用gain
model-based calibration method,使用z-transformed对特征进行归一化。 - 使用ReliefF方法对特征空间进行选择,没有选择DLAT的全部空间。
- 使用高斯朴素贝叶斯分类器进行分类。
迁移学习
领域 (Domain): 是进行学习的主体。领域主要由两部分构成: 数据和生成这些数据的概率分布。通常我们用花体 D 来表示一个 domain,用大写斜体 P 来表示一个概率分布。
特别地,因为涉及到迁移,所以对应于两个基本的领域: 源领域 (Source Domain) 和目标领域 (Target Domain)。源领域就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标领域就是我们最终要赋予知识、赋予标注的对象。知识从源领域传递到目标领域,就完成了迁移 。
条件迁移学习框架
when: 当由他们自己的数据训练,仅实现低于chance-level的准确性(即两类分类问题中的50%)。
how: 本研究基于其ReliefF排序的情感相关特征空间来表征主体间的相似性。相似性被定义为皮尔逊相关系数的值。即相关系数值越大,受试者越相似。
what: 本研究将所选样本集和相似样本集的数据连接在一起,开发一个更一般化但信息量更大的特征空间。
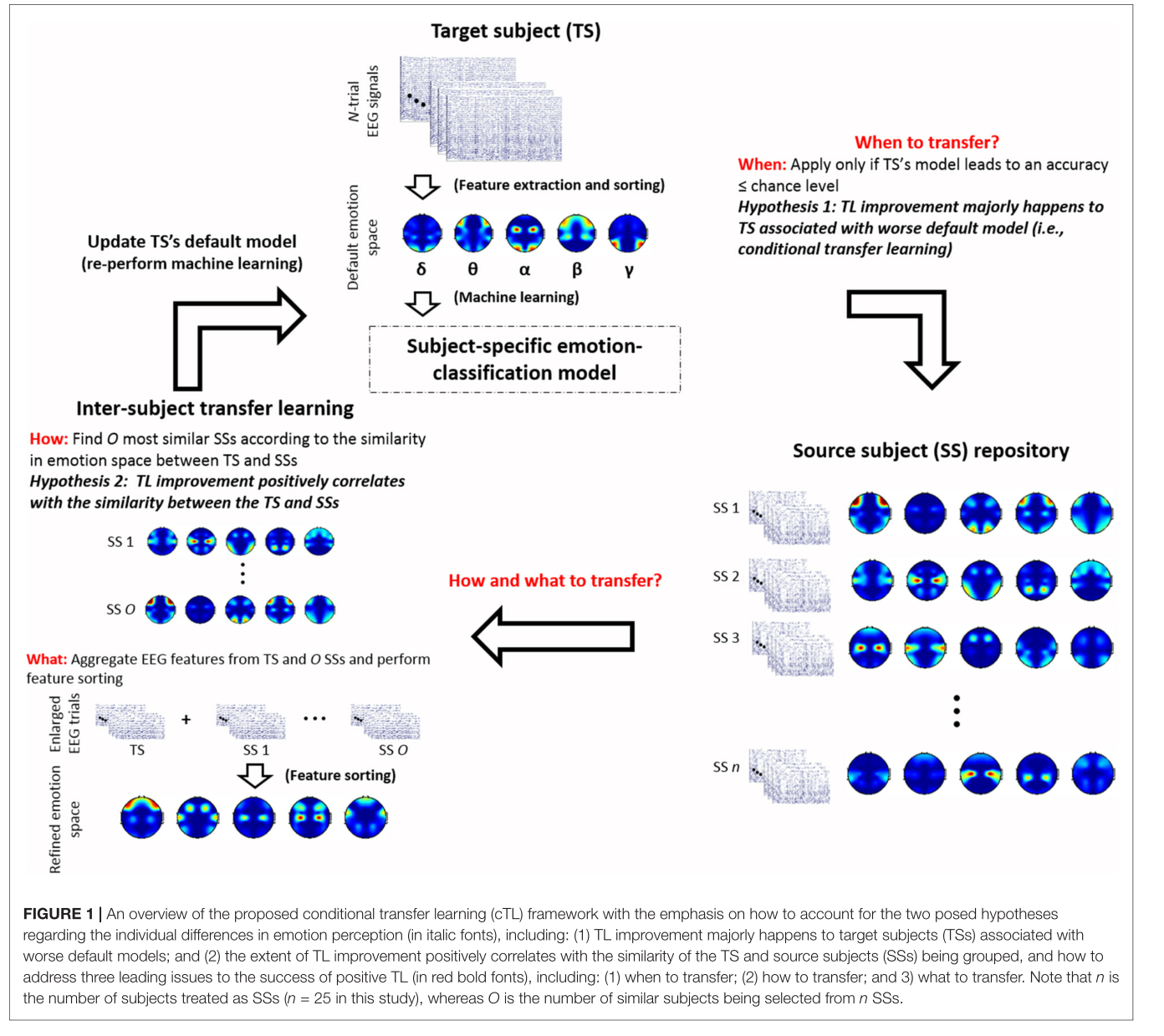
条件迁移学习框架前提: 数据集共26人,25人看成源领域,1人看作目标领域。每个人数据由16次实验组成,实验中采用LTO方法,即每次利用15次实验数据去预测另一次实验的数据。
- 计算源域和目标域的相似性,便于后续利用。
- 选择O个最相似的人,和当前受试者的15次实验组成新的数据集,即O*16 + 15。
- 为了在分类器建模过程中消除类别不平衡问题的影响,该步骤在500次重复的训练中随机选择类别平衡样本,试图产生最优但公平的训练模型。每次重复应用5倍交叉验证并且添加一个特征,即一次添加一个具有高ReliefF分数的特征。
- 使用朴素高斯贝叶斯分类器进行重新分类。
结果
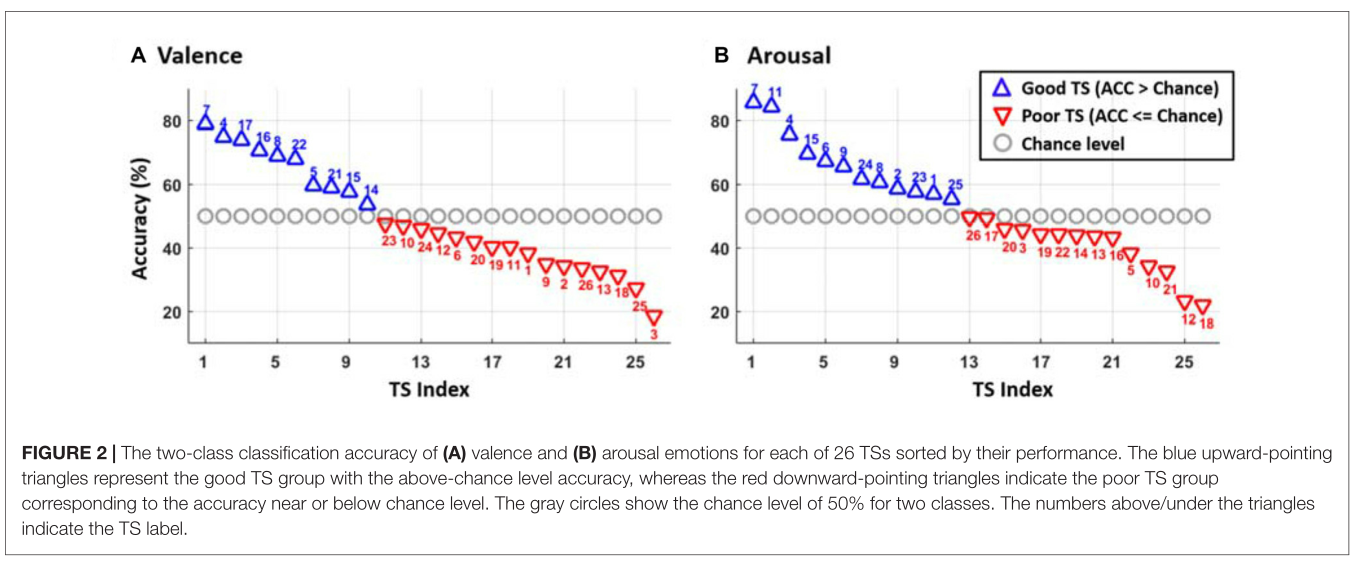
图2:纵轴为acc,横轴为目标域index。左边是valence,右边是arousal,灰色线是50%acc,也就是瞎蒙的水平。蓝色代表自身预测就比较好的,红色代表自身预测比较差的,数字代表第几位受试者。
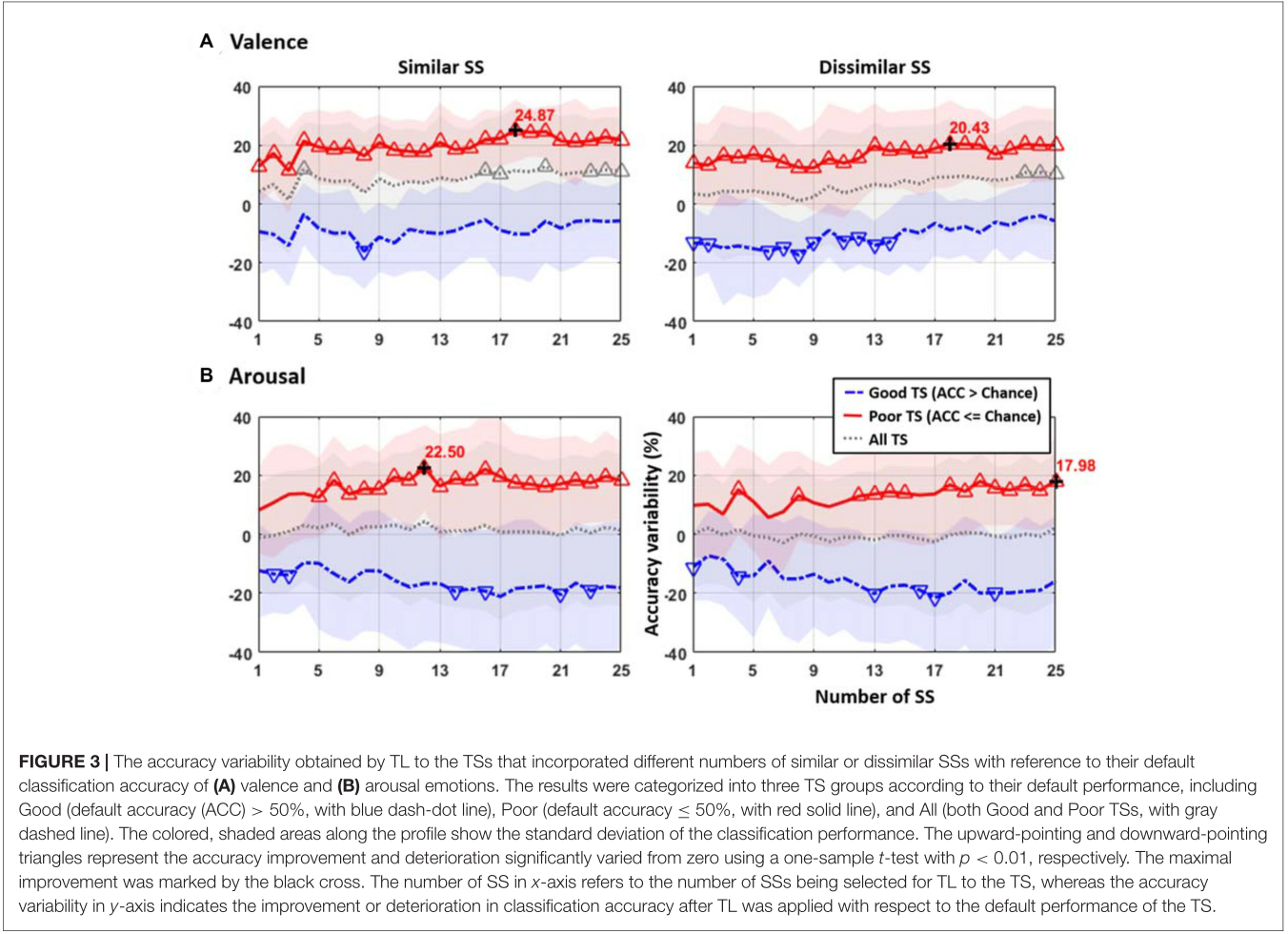
图3:横轴是添加源域的人数,也就是说使用迁移学习方法,我们决定引入源域多少人(1-25)。纵轴是效果,有提升也有下降。第一行是valence,第二行是arousal。第一列是添加的相似人数,第二列是添加的不相似人数。红色线代表原始数据效果不好使用迁移学习的变化,蓝色线代表原始数据效果好的使用迁移学习变化。灰色线是目标域所有的数据使用迁移学习后的结果。三角代表得出的最高点或者最低点。
首先可以看出,本身效果就不错的实验,添加了其他人的数据,结果都会变差。这也证明了条件迁移的必要性。同时,添加相似的数据效果是比添加不相似的效果更好,但是二者最终趋于统一。
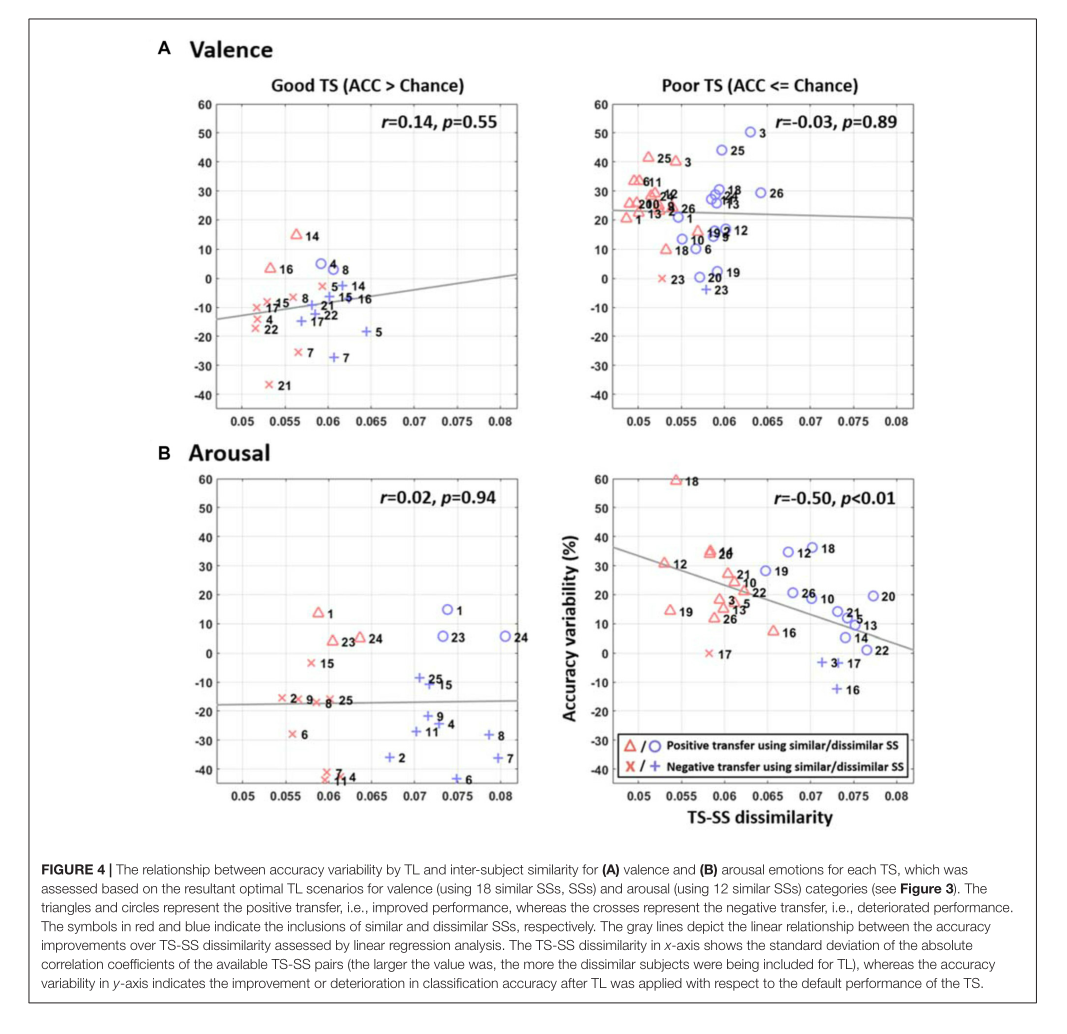
图4:该图是通过上图的添加人数得出的新结果,valence为18人,arousal为12人。横轴为不相似性,即离得越远越不相似。纵轴为acc的变化率。灰色直线为线性回归线,三角形和原形均表示正迁移,叉号和加号均表示负迁移。红色代表添加相关数据,蓝色代表添加不相关数据。图中数字为受试者编号。第一列为原本结果优秀的人,第二列为原本结果比较差的人。
从图中可以看到,蓝色普遍靠右,很容易理解,因为不相似性肯定更大。同时右侧结果普遍提升比较大,也证明了迁移学习对原本效果比较差的有较大提升。
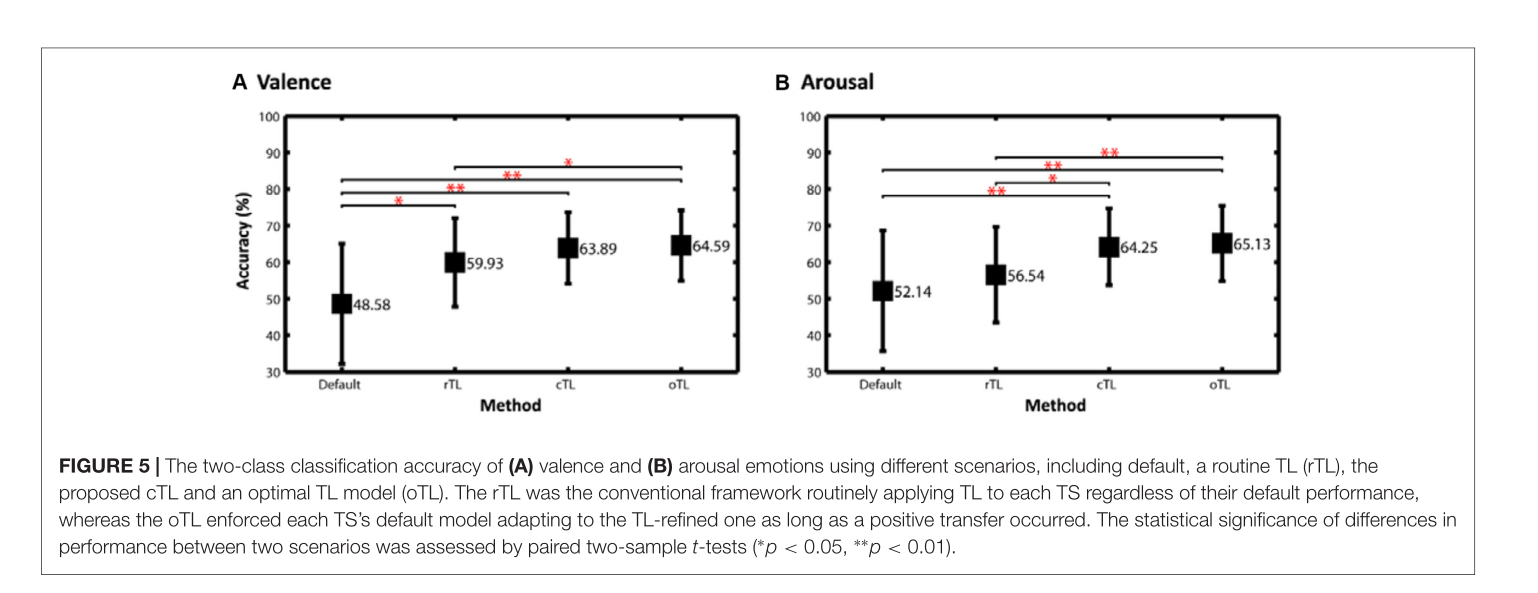
图5:图为4种方法的对比,default即最原始的方法,rTL则是将所有的数据都进行迁移学习,cTL则是当结果低于50%的时候进行迁移学习,oTL比较鸡贼,先迁移学习,如果发生了正迁移则采用,否则不适用迁移学习。和*是两个实验的假设检验。
讨论
正迁移的时机
因此,本研究的动机是提出有条件的迁移学习,假设迁移学习将使结果表现较低的受试者受益,而不是那些表现相对较好的受试者。本研究直观地采用了高于或低于机会水平(即50%)的默认标准来推断是否进行迁移。
正迁移的相似性数据和不相似性数据
迁移学习的分类模型通过利用5-10个相似受试者获得了立即的改进,但是将所有可用的受试者集合在一起并不能绝对保证在使用相似或不相似源域受试者的情况下最大程度地提高性能。
这项研究将这一问题设为将来单独的研究,通过添加更多的受试者数据寻找规律。