摘要:大型公司需要实时监视其应用程序和服务中的各种指标(例如,“页面浏览量”和“收入”)。在Microsoft,我们开发了时间序列异常检测服务,该服务可帮助客户不断的监视时间序列并及时提醒潜在的事件。在本文中,为了解决时间序列异常检测的问题,我们提出了一种基于谱残差(SR)和卷积神经网络(CNN)的新算法。我们的工作是尝试将视觉显着性检测域中的SR模型首次迁移到时间序列异常检测中。此外,我们创新地将SR和CNN结合在一起以改善SR模型的性能。与公共数据集和Microsoft数据集的最新基准(只使用了周期相关的历史数据,没有使用上同周期相邻时刻的历史数据)模型相比,我们的方法获得了优异的实验结果。
关键词:异常检测,无监督,时间序列
论文背景与意义
异常检测旨在发现意外事件或数据中的稀有项。它在许多工业(以盈利为主的)应用中都很流行,并且它也是数据挖掘中的重要研究领域。准确的异常检测可以触发及时的故障排除,从而避免企业亏损,并维护了公司的声誉和品牌。为此,大公司开始建立异常检测服务来监视其业务,产品和服务的健康状况。例如,雅虎发布了EGADS系统 ,可以自动监视数百万个不同Yahoo属性的时间序列并发出警报。在Microsoft,我们构建了异常检测服务来监视例如Bing,Office和Azure等应用的数百万个指标,这使工程师能够更快地解决问题。然而在设计时序异常检测的工业服务时面临了许多挑战:
挑战1:缺乏标签。为了给单个业务场景提供异常检测服务,系统必须同时处理数百万个时间序列。用户没有简单的方法能够手动标记每个时间序列。而且,时间序列的数据分布是不断变化的,这要求系统能识别出以前从未出现过类似数据的模式。这使得有监督模型在工业场景中应用不足。
挑战2:泛化。需要监视来自不同业务场景的各种时间序列。如图1所示,有几种典型的时间序列模式类别。对于工业异常检测服务来说,在各种模式下正常工作是非常的重要。然而,对于不同的模式,现有的方法还没有得到足够的概括。例如,Holt winters模型(基于时间序列中当前已有的数据来预测其之后的走势)在(b)和(c)中总是表现出差的结果。 Spot模型 在(a)中总是表现出差的结果。因此,我们需要找到通用性更好的解决方案。
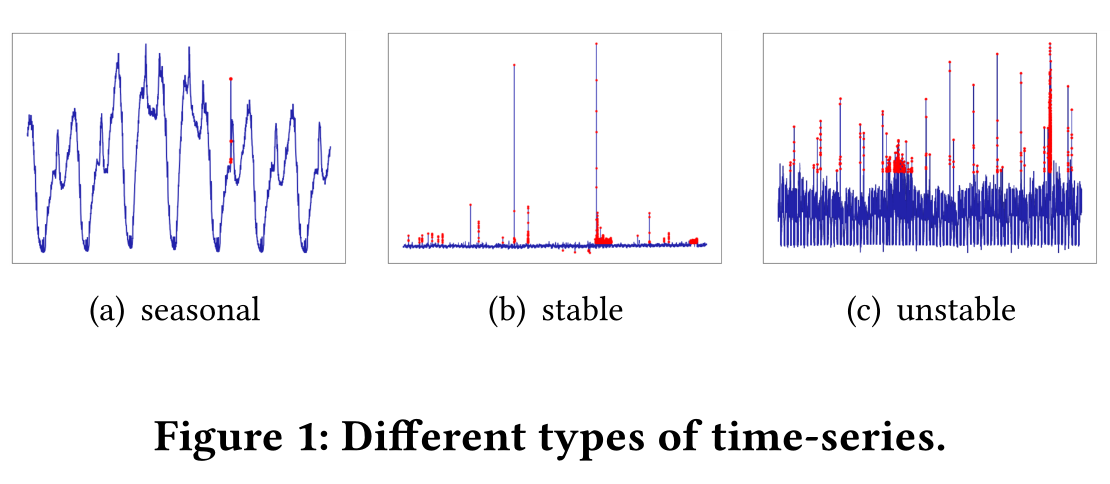
挑战3:效率。在应用程序中,监视系统必须几乎实时处理数百万甚至数十亿个时间序列。特别是对于分钟级别的时间序列,异常检测过程需要在有限的时间内完成。因此,效率是在线异常检测服务的主要前提之一。即使具有较大时间复杂度的模型在准确性方面表现出色,但在在线情况下它们通常很少使用。
论文的目标
为了解决上述问题,我们的目标是开发一种准确,高效且通用的异常检测方法。传统的统计模型由于准确性不高,不足以用于工业应用。有监督模型的准确性更高,但是由于缺少标记数据(人工标记的开销太大),在我们的场景中它们也是不足的。还有一些无监督的方法,例如Luminol(用于时间序列数据分析的python库。将时间序列分为多个块,并使用相似块的频率来计算异常分数)和DONUT(一种基于变分自动编码器(VAE)的无监督异常检测方法)。但是,这些方法太耗时或参数敏感。因此,我们旨在以另一种无监督的方式开发一种同时兼顾准确性,效率和通用性的模型。
异常检测系统架构
整个系统由三个主要部分组成:数据提取,实验平台和在线计算。
首先介绍整个流程。用户可以将时间序列导入到系统来注册监视任务。支持从不同的数据源(包括Azure存储,数据库和在线流数据)提取时间序列。提取人员负责根据指定的粒度(例如分钟,小时或天)更新每个时间序列。时间序列点通过Kafka进入流传输管道,并存储到时间序列数据库中。异常检测处理器在线计算传入的时间序列点的异常状态。在监视业务指标的常见方案中,用户也可以查看时间序列数据。例如,Bing团队提取了表示不同市场和平台使用情况的时间序列。发生事件时,警报服务会整理相关时间序列的异常,然后通过电子邮件和传呼服务将其发送给用户。整合的异常事件总体状态信息将帮助用户缩短诊断问题的时间。下图展示了系统的总体流水线。
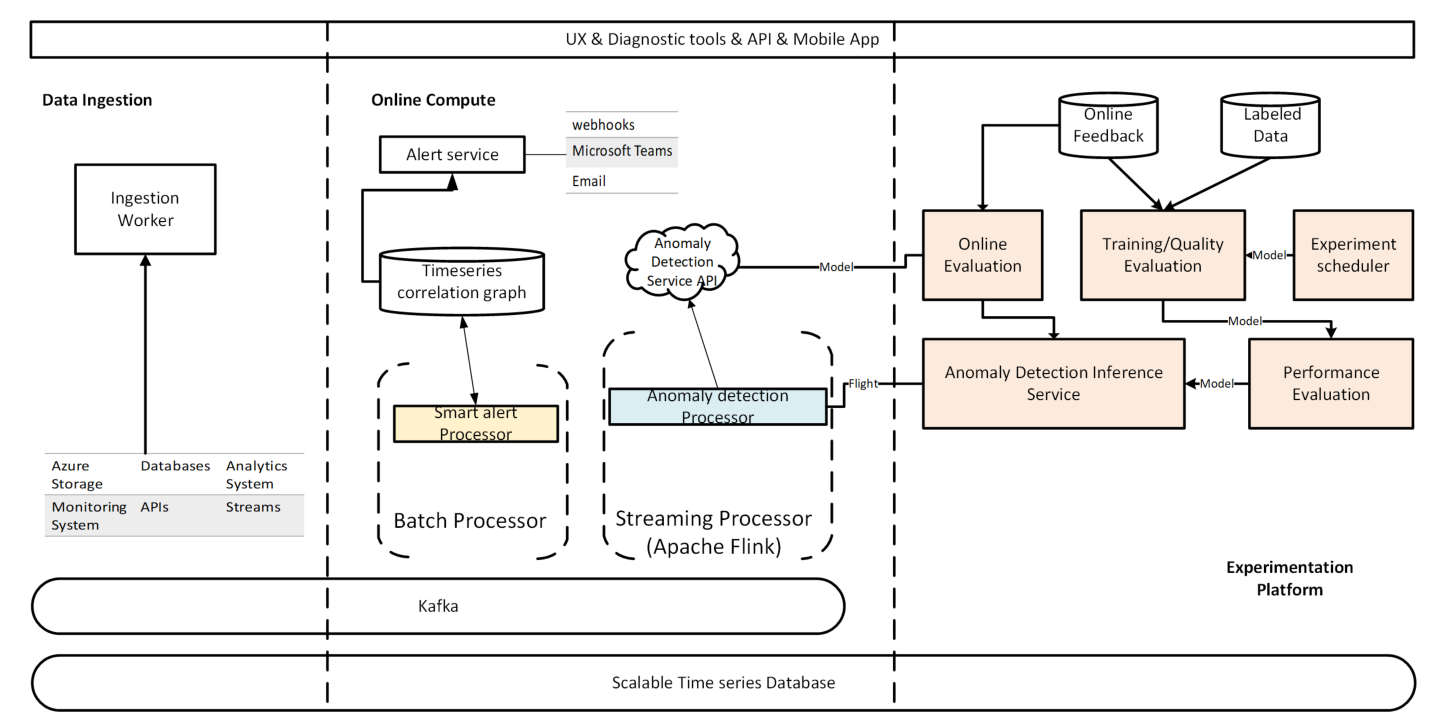
2.1数据提取
用户可以通过创建数据源来注册监视任务。每个数据点均由“连接字符串”和“粒度”标识。连接字符串用于将用户的存储系统连接到异常检测服务。粒度表示数据Feed(采集)的更新频率;最小粒度为一分钟。提取任务将根据给定的粒度把时间序列的数据点提取到系统中。例如,如果用户将分钟设置为粒度,则提取模块将每分钟创建一个任务来提取一个新的数据点。时间序列点被吸收到influxDB(时间序列数据库)和Kafka(流处理管道)中。该模块的吞吐量达到每秒10,000到100,000个数据点左右。
2.2在线计算
在线计算模块在进入管道(pipeline)后将立即处理每个数据点。为了检测输入点的异常状态,需要时间序列数据点的滑动窗口。因此,我们使用Flink来管理内存中的点以优化计算效率。流媒体管道每天处理超过400万个时间序列。每分钟最大吞吐量可以达到400万。异常检测处理器检测每一个时间序列的异常。实际上,单个异常不足以使用户有效地诊断其服务。因此,智能警报处理器将不同时间序列的异常关联起来,并相应地生成事件报告。
Flink支持流处理和窗口事件时间语义,Flink能够高吞吐量和低延迟;
Kafka支持高吞吐量,每秒数百万的消息,支持通过Kafka服务器和消费机集群来分区消息。
2.3实验平台
我们建立了一个实验平台来评估异常检测模型的性能。在我们部署新模型之前,将在平台上进行离线实验和在线A / B测试。用户可以把某个点标记为异常或正常。为人工编辑人员提供了标签服务。编辑者将首先标记单个时间序列的真实异常点,然后根据特定模型的异常检测结果标记错误的异常点。已标记的数据用于评估异常检测模型的准确性。我们还评估了平台上每种模型的效率和通用性。如果验证模型有效,则平台会将其公开为Web服务并将其托管在K8s(全称Kubernetes,用于管理云平台中多个主机上的容器化应用,轻松高效地管理这些集群)上。
2.4系统应用
在微软,通常需要监视业务指标并迅速采取措施以解决突发的异常问题。为了解决该问题,我们构建了一个可伸缩的系统,能够监视来自各种数据源的分钟级时间序列。提供自动诊断意见以帮助用户有效地解决其问题。
例子:Outlook反垃圾邮件团队曾经利用基于规则的方法来监视其垃圾邮件检测系统的有效性。但是,此方法不易于维护,并且在某些地理位置有很差的效果。因此,他们将关键指标纳入我们的异常检测服务,以监控其垃圾邮件检测模型在不同地理位置的有效性。通过我们的API,他们已将异常检测功能集成到Office DevOps平台中。通过使用此自动检测服务,与原始的基于规则的解决方案相比,他们覆盖了更多的地理位置,并且收到的误报案件更少。
为什么要使用SR-CNN
正如引言中所强调的,我们的挑战是开发一种没有标签数据的高效通用算法。受计算机视觉领域的启发,我们采用谱残差(SR)模型,这是一种基于快速傅立叶变换(FFT)的方法。 SR方法是无监督的,并且已被证明在视觉显着性检测应用中非常有效。因为异常点在视觉上通常很明显,因此我们认为视觉显着性检测任务和时间序列异常检测任务在本质上是相似的。此外,最近的显着性检测研究表示当有足够的标签数据可用时更倾向于使用卷积神经网络(CNN)进行端到端训练。然而,由于难以在线收集大规模的标签数据,因此单独使用CNN模型对我们的应用来说是不可行的。作为一种折衷,我们提出了一种新的方法SR-CNN,该方法将CNN直接应用于SR模型的输出。 CNN负责学习区分规则,以替换原始SR解决方案中采用单个阈值来判断异常。在SR结果上学习CNN模型比在原始输入序列上学习问题要容易得多。在以下小节中,我们分别介绍SR和SR-CNN方法的细节。
SR(谱残差)
SR算法包括三个主要步骤:(1)傅里叶变换以获得对数幅度谱; (2)频谱残差的计算; (3)傅立叶逆变换,将序列变换回空间域。
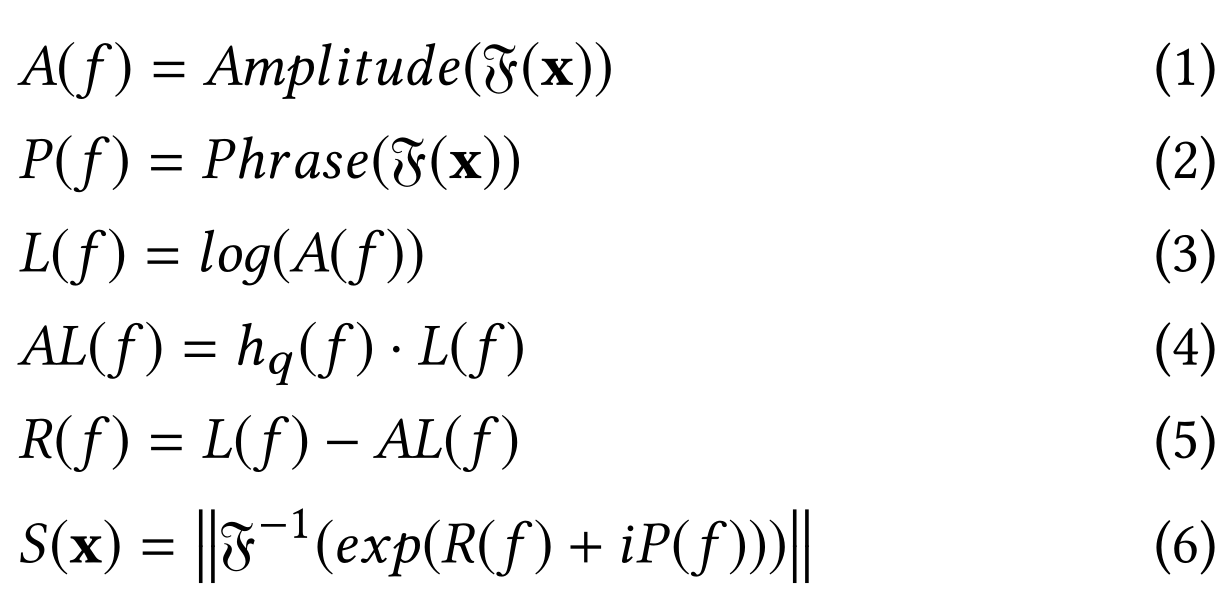
数学上,给定序列x,我们有
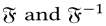 分别表示傅立叶变换(时域到频域的变换,而这种变换是通过一组特殊的正交基来实现的)和傅立叶逆变换。x是形状为n×1(n维向量)的输入序列;
分别表示傅立叶变换(时域到频域的变换,而这种变换是通过一组特殊的正交基来实现的)和傅立叶逆变换。x是形状为n×1(n维向量)的输入序列;A(f)是序列x的幅度谱;P(f)是序列x的相位谱;L(f)是A(f)的对数表示(对幅度谱取对数);AL(f)是L(f)的平均对数谱,可以通过用hq(f)卷积(两个相同大小的矩阵对应元素相乘后求和,乘积的和就生成了feature map中的一个像素,当一个像素计算完毕后,移动一个像素取下一个区块执行相同的运算。当无法再移动取得新区块的时候,对feature map的计算就结束了)输入序列来近似得出。其中hq(f)是一个q×q矩阵,定义为:
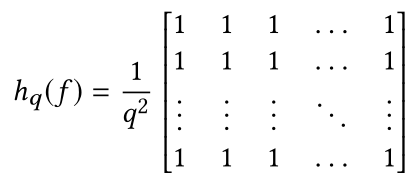
R(f)是谱残差,即对数谱L(f)减去平均对数谱AL(f)。利用剩余谱和相位谱进行傅立叶逆变换将序列转移回空间域,得到序列S(x)称为显著图(saliency map)。(傅里叶变换一般涉及到复数,也就是说一个实数被变换为一个具有实部和虚部的复数。通常虚部只在一部分领域有用,比如将频域变换回到时域和空域(像素域)上)
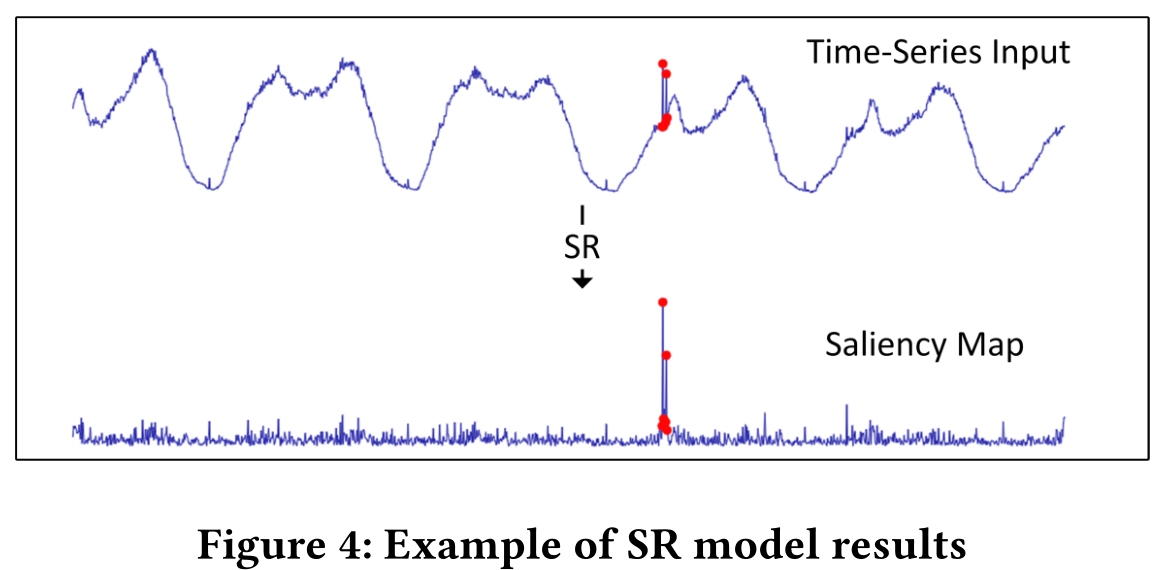
图4显示了经过SR处理后的原始时间序列和相应的显著性图的示例。如图所示,显著性图中的变化点(以红色显示)比原始输入中的变化点明显得多。基于显著性图,很容易利用简单的规则正确注释异常点。我们采用简单的阈值τ表示异常点。给定显著性图S(x),输出序列O(x)的计算公式为:
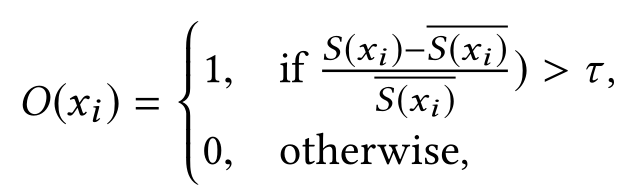
其中xi表示序列x中的任意点; S(xi)是显著图中的对应点; S(xi) ba 是S(xi)之前z个点的局部平均值。
在实际应用中,FFT(快速傅里叶变换)操作是在序列的滑动窗口内进行的。此外,我们希望该算法能够发现低延迟的异常点。也就是说,给定流x1,x2,…,xn,其中xn是最近的点,我们想尽快分辨xn是否是一个异常点。但是,如果目标点(想要分辨的点)位于滑动窗口的中心,则SR方法效果更好。因此,在将序列输入到SR模型之前,我们在xn之后添加了几个估计点。估计点xn+1的值由下式计算:
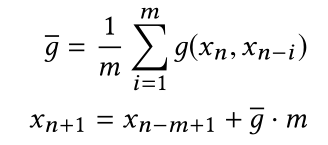
其中g(xi,xj)表示点xi和xj两点之间的直线的斜率; g ba表示先前点的平均斜率(从1到m的xi和xj之间的平均斜率)。m是前面考虑的添加点的个数,我们在实现中将m=5。我们发现,第一个估计点起着决定性的作用。因此,我们复制K次点xn+1,然后把它添加到序列的尾部。总而言之,SR算法只包含3个超参数,即滑动窗口大小ω,估计点个数κ,异常检测阈值τ。我们根据经验设置了它们,并在实验中展示了它们的鲁棒性。因此,SR算法对于在线异常检测服务来说是一种很好的选择。
SR-CNN
原始的SR方法利用显著性图上的单个阈值来检测异常点,如上图所定义。然而,该规则过于简单,人们自然会寻求更复杂的决策规则。我们的理念是在精心设计的合成数据上训练一个判别模型作为异常检测器。通过将不包含在评估数据中的异常点注入到显著性图集合中,来生成合成数据。注入点标记为异常,其他点标记为正常。具体地说,我们在时间序列中随机选取几个点,计算注入值来代替原始点,得到其显著性图。异常点值的计算方法为:
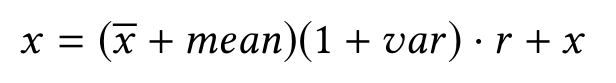
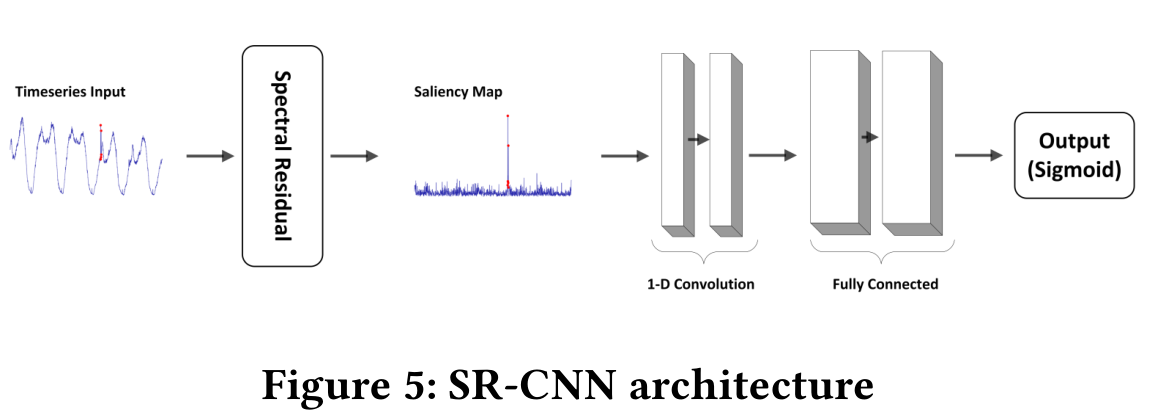
其中x ba是前几个点的局部平均值;mean(均值)和var(方差)是当前滑动窗口内所有点的均值和方差;r〜N(0,1)是随机抽样的。我们选择CNN作为我们的判别模型架构。CNN是用于显著性检测的常用监督模型。但是,由于我们的场景中没有足够的标记数据,因此我们基于显著图而不是原始输入来应用CNN,这使得异常标注问题变得更加容易。在实践中,我们收集合成异常的生产时间序列作为训练数据。好处是检测器可以适应时间序列分布的变化,而无需人工标记的数据。在我们的实验中,我们总共使用了6,500万个点进行训练。 SR-CNN的体系结构如图5所示。该网络由两个一维卷积层(滤波器大小等于滑动窗口大小ω)和两个全连接层组成。第一个卷积层的信道大小等于ω;而在第二个卷积层中,通道大小增加了一倍。在输出Sigmoid之前,要堆叠两个全连接层。交叉熵被用作损失函数。训练过程中使用了SGD(随机梯度下降)优化器。
数据集
使用三个数据集来评估了SR-CNN模型。KPI和Yahoo是常用于评价时间序列异常检测性能的公共数据集;而Microsoft是在产品中收集的内部数据集。这些数据集涵盖了不同时间间隔的时间序列。在这些数据集中,异常点标记为正样本,正常点标记为负样本。这些数据集的统计数据如表1所示。
KPI由AIOps发布。该数据集由多条带有异常标签的KPI曲线组成,大部分KPI曲线相邻两个数据点之间的间隔为1分钟,部分KPI曲线的间隔为5分钟。
1 | 数据集 |
Yahoo是 Ya-hoo lab发布的用于异常检测的开放数据集。时间序列曲线中的一部分是人工合成的(即模拟的),另一部分来自雅虎服务的真实流量。模拟曲线中的异常点由算法生成,真实交通曲线中的异常点由编辑人员手动标注。所有时间序列的间隔为一小时。
1 | https://yahooresearch.tumblr.com/post/114590420346/a-benchmark-dataset-for-time-series-anomaly |
Microsoft是从微软内部异常检测服务中获得的数据集。我们随机选取一组时间序列进行评价。选择的时间序列反映了不同的KPI,包括收入、活跃用户、页面浏览量等,异常点由客户或编辑手动标注,这些时间序列的间隔为一天。
指标
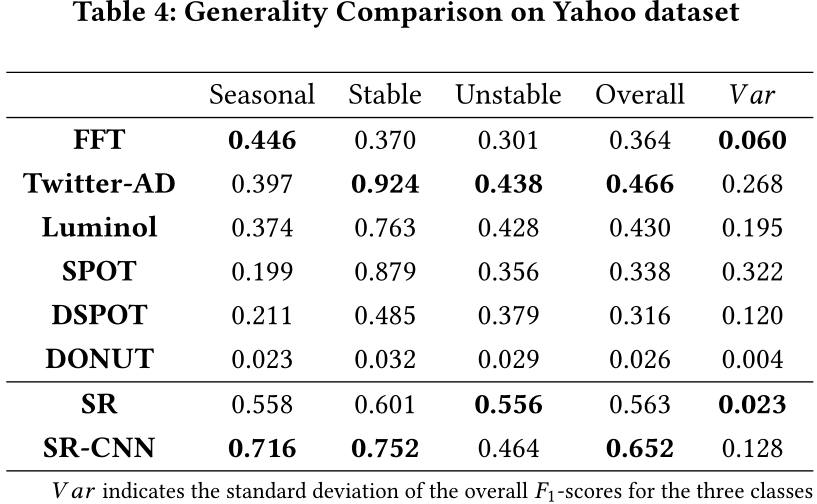
我们从准确性、效率和通用性三个方面对我们的模型进行了评估。我们使用 precision(精确率)、recall(召回率)和F1-score(F1得分)来表示我们模型的准确性。对于那些应用于在线服务的模型。在这个系统中,我们每秒必须完成数十万次计算。模型的延迟需要足够小,这样才不会阻塞整个计算管道。在我们的实验中,我们评估了三个数据集上的总执行时间,以比较不同异常检测方法的效率。除了准确性和效率,我们在评价时也强调通用性(泛化能力)。如前所述,工业异常检测模型应该能够处理不同类型的时间序列。为了评估通用性,我们将Yahoo数据集中的时间序列手工划分为三大类(如图1所示的季节性、稳定和不稳定),并分别比较不同类别的F1得分。
Positive正(阳性) Negative负(阴性) True真 False假
在异常检测中,P和N一般是针对预测来说的,而Positive正类指的是你更关心的那一类,即异常,Negative负类就是指正常。总结来说就是:P指预测为异常,N指预测为正常
T和F是针对预测与实际的比较结果,True真是指正确匹配,具体来说就是:你预测它为正,它实际结果也为正,你预测它为负,它实际也为负,False假就是错误匹配。
TPR:真正类率,又叫真阳率,代表预测是异常实际也是异常的样本数,占实际总异常数的比例—值越大 性能越好
FPR:假正类率,又叫假阳率,代表预测是异常但实际是正常的样本数,占实际正常总数的比例—值越小 性能越好
P(precision):精确率,代表预测是异常,实际也是异常的样本数,占预测是异常的总数的比例—值越大 性能越好
R(recall): 召回率,意义同TPR—值越大 性能越好
F: P和R的加权调和平均,常用的是F1值(F1-score)—值越大 性能越好
A(accuracy):正确率,与精确率的区别是,不仅考虑异常类也考虑正常类,即所有匹配样本数,占所有样本的比例—值越大 性能越好
FP(误报:正常被误报成异常) FN(异常漏报:异常被误报成正常)
SR/SR-CNN实验
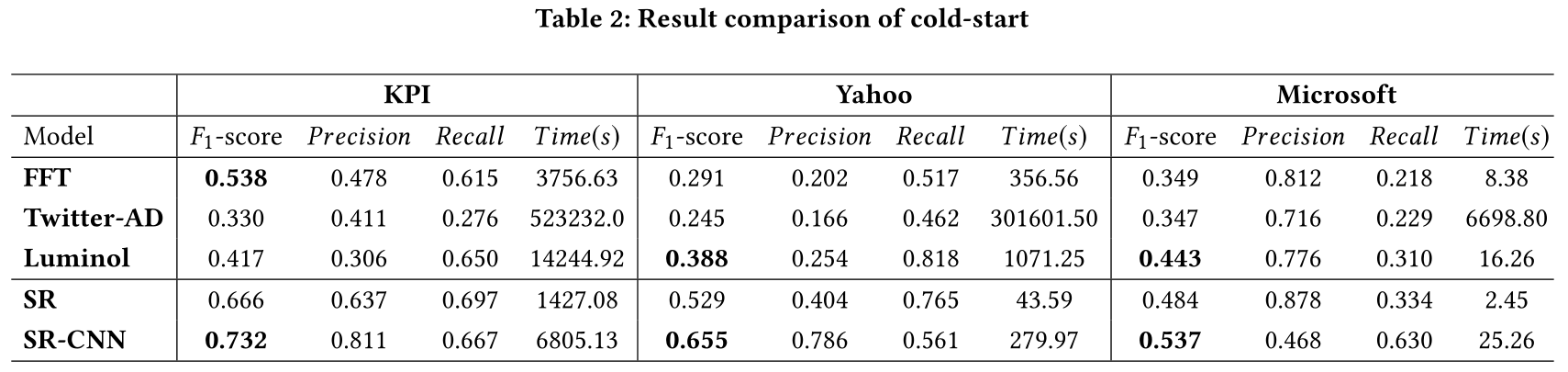
我们将SR和SR-CNN与最新的无监督时间序列异常检测方法进行了比较。基线模型包括FFT(快速傅立叶变换)、Twitter-AD(推特异常检测)、Luminol(LinkedIn异常检测)、DONUT、SPOT和DSPOT。在这些方法中,FFT、Twitter-AD和Luminol不需要额外的数据就可以启动,所以我们将所有的时间序列作为测试数据,在冷启动(没有任何先验知识,协同过滤推荐算法中被广泛关注的一个经典问题)的情况下对这些模型进行了比较。另一方面,Spot、DSPOT和Donut需要额外的数据来训练他们的模型。因此,我们将每个时间序列的点按时间顺序一分为二。前半部分用来训练无监督模型,后半部分用来进行评估,Donut可以利用额外的标记数据来提高异常检测性能。然而,由于我们的目标是在完全无监督的情况下获得公平的比较,所以我们在实现中不使用额外的标记数据。
对于SR和SR-CNN,我们对超参数进行了经验设置。在SR中,Hq(f)中q被设置为3,z的局部平均数z被设置为21,阈值τ被设置为3,估计点数κ被设置为5,对于滑动窗口大小ω,KPI设置为1440,雅虎设置为64,微软设置为30。对于SR-CNN,q、z、κ和ω被设置为相同的值。
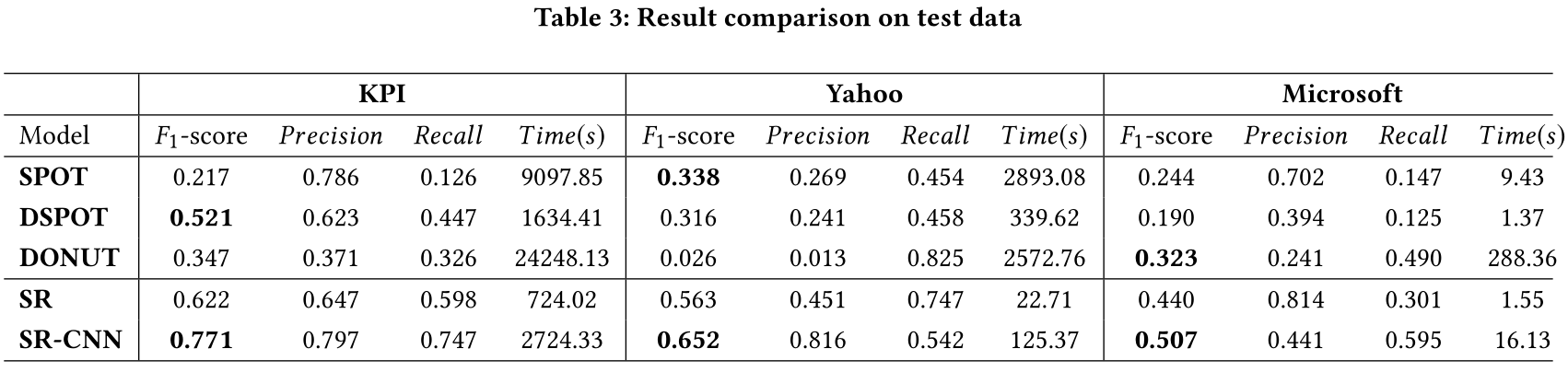
我们分别报告(1)F1-score;(2)Precision;(3)Recall;(4)每个数据集的CPU执行时间。我们可以看到,SR的性能明显优于当前最先进的无监督模型。此外,SR-CNN在三个数据集上都取得了进一步的改进,这表明了用CNN鉴别器取代单一阈值的优势。表2显示了冷启动情况下FFT、Twitter-AD和 Luminol的比较结果。与基准解决方案获得的最佳结果相比,我们在KPI数据集、Yahoo数据集和Microsoft数据集上的F1-score分别提高了36.1%、68.8%和21.2%。表3展示了那些需要在数据集的前半部分(不包括标签)上训练的无监督模型的比较结果。如表3所示,与最先进的结果相比,F1-Score在KPI数据集上提高了48.0%,在Yahoo数据集上提高了92.9%,在Microsoft数据集上提高了57.0%。此外,表2和表3中的总CPU执行时间表明,SR是最有效的方法。为了进行通用性比较,我们在人工分类为三类的Yahoo数据集的后半部分上进行了实验。表4分别报告了Yahoo数据集不同类别的F1-score。SR和SR-CNN在不同的时间序列模式上取得了突出的结果。SR是这三个类别中最稳定的一个。SR-CNN也表现出良好的泛化能力。
SR+DNN
在先前的实验中,我们可以看到SR模型在无监督的异常检测情况下表现出了很好的结果。但是,在其他人已完成的工作表明,当异常标签可用时,我们可以获得更令人满意的结果,因此,我们想知道我们的方法是否有助于监督模型。具体而言,我们将SR的中间结果作为监督异常检测模型中的附加功能。我们对AIOPS中对KPI数据集进行了广泛的研究后,采用基于DNN的有监督模型,该模型是AIOPS数据竞赛的第一名。 DNN体系结构由输入层,输出层和两个隐藏层组成。
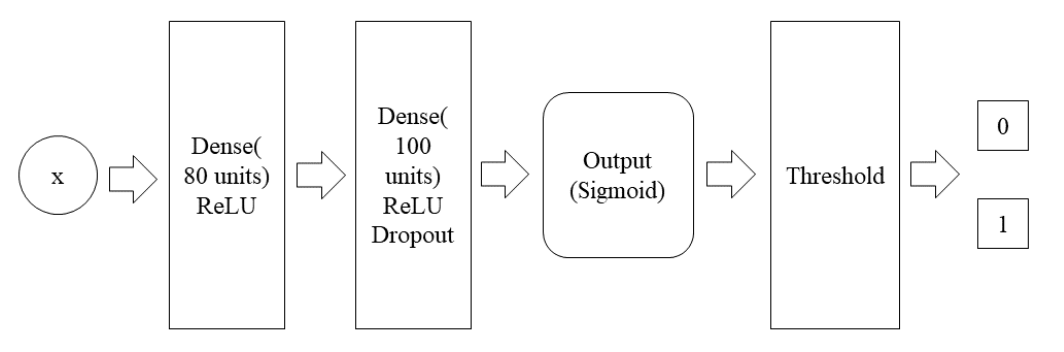
我们在第二个隐藏层之后增加了一个dropout layer(丢弃层),并将丢弃率设置为0.5。此外,我们将L1 = L2 = 0.0001正则化所有层的权重。由于模型的输出表示数据点异常的可能性,因此我们在训练集上学习最佳阈值。
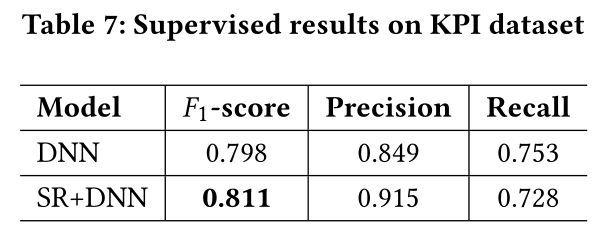
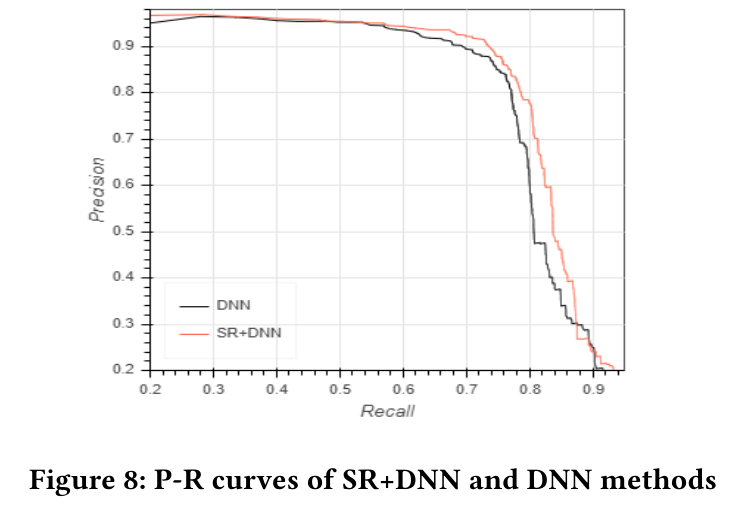
实验结果如表7所示。我们可以看到,SR功能为DNN模型带来了F1-score提高1.6%的效果。尤其是,基于SR的DNN模型在KPI数据集上建立了一个最先进的模型。据我们所知,这是迄今为止KPI数据集上报告的迄今为止最好的结果。此外,我们绘制了SR + DNN和DNN方法的P-R曲线(右上凸效果越好)。如图8所示,在各种阈值上,SR + DNN始终优于DNN。
总结
时间序列异常检测是保证在线服务质量的关键模块。在实际应用中,一个高效、通用、准确的异常检测系统是必不可少的。在本文中,我们介绍了微软的一项时序异常检测服务。在生产过程中,每分钟最多可从400万个时间序列中检测到异常。此外,我们还首次将谱残差模型应用于时序异常检测任务,并创新性地将谱残差模型与CNN模型相结合,取得了较好的效果。