用自监督学习方法揭示临床上EEG信号的结构
Objective:
监督学习方案常常受到可用标记数据数量的限制。这种现象在临床相关数据中尤其成问题,如脑电图(EEG),在这些数据中,根据专业知识来标记代价昂贵。目前,设计用于脑电图数据学习的深度学习架构产生了相对较浅的模型,其性能至多与传统的基于特征的方法相似。然而,在大多数情况下,会有大量没有标记的数据。通过从这些未标记的数据中提取信息,尽管无法获取标签,但仍然有可能通过深度神经网络达到竞争性能。
Approach:
本文研究了自监督学习(SSL),一种在未标记数据中发现结构的技术,以学习脑电信号的表示。 具体来说,我们探索了两个基于时间上下文预测以及对比预测编码在两个临床相关问题的表现:基于脑电图的睡眠分期和病理检测。我们在两个拥有数千条记录的大型公共数据集上进行了实验,并用纯监督和手工设计的方法进行了baseline的比较。
Main results:
在SSL学习特征上训练的线性分类器在低标记数据系统中的性能始终优于纯监督的深层神经网络,同时在拥有所有标签时都达到有竞争力的性能。 此外,用每种方法学习的嵌入揭示了与生理和临床现象相关的明确的潜在结构,如年龄效应。
1. Introduction
Electroencephalography (EEG) 脑电信号作为一种重要的生理模态,在医疗场景中使用的非常广泛,如睡眠分阶、心理压力监测等。因此,设计模型可以进行分类,检测,并最终“理解”生理数据是必要的。传统上,这种类型的建模主要依赖于监督方法,其中需要大量带注释的数据集来训练具有高性能的模型。
当前的机器学习方法大多依赖于标注信息,这种对标注信息的过度依赖有如下危险:
- 数据的内部结构远比标注提供的信息要丰富,因此通常需要大量的训练样本,但得到的模型有时是较为脆弱的。
- 在高维分类问题上,我们不能直接依赖监督信息;同时,在增强学习等问题上,获取标签的成本非常高。
- 标签信息通常适用于解决特定的任务,而不是可以做为知识一样可以重新利用。
“自监督学习”(SSL)是一种无监督学习方法,它从未标记的数据中学习表示,利用数据的结构来提供监督。这里介绍的自监督学习方法是通过构造辅助任务(pretext)来辅助下游任务(downstream)。下游任务是我们真正感兴趣的任务,但是没有注释或注释有限。另一方面,辅助任务必须与下游任务有充分的关联,以便使用类似的表示来训练它,重要的是,必须能够仅使用未标记的数据为这个辅助任务生成注释。
在这篇论文中,我们研究自我监督的使用作为从脑电图数据学习表征的一般方法。首次对多种类型的脑电图记录进行了SSL任务的详细分析。我们的目标是回答以下问题:
- 哪些好的SSL任务能够捕获脑电图数据中的相关结构?
- 就下游分类性能而言,SSL特性与其他非监督和监督方法相比如何?
- SSL学到的特性是什么?具体来说,SSL能否从未标记的脑电图中捕获与生理和临床相关的结构?
self-supervised learning两大流派
构造辅助任务,辅助下游任务
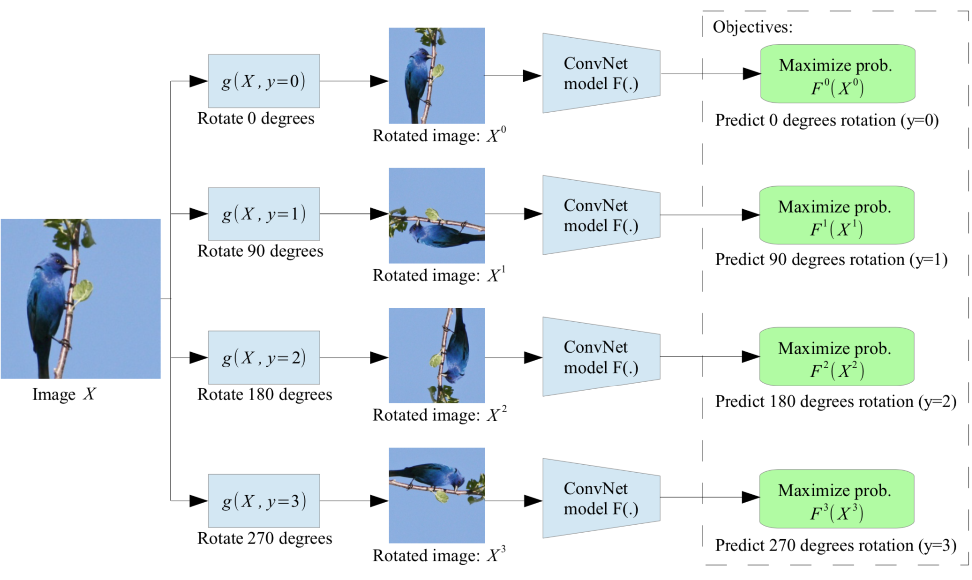
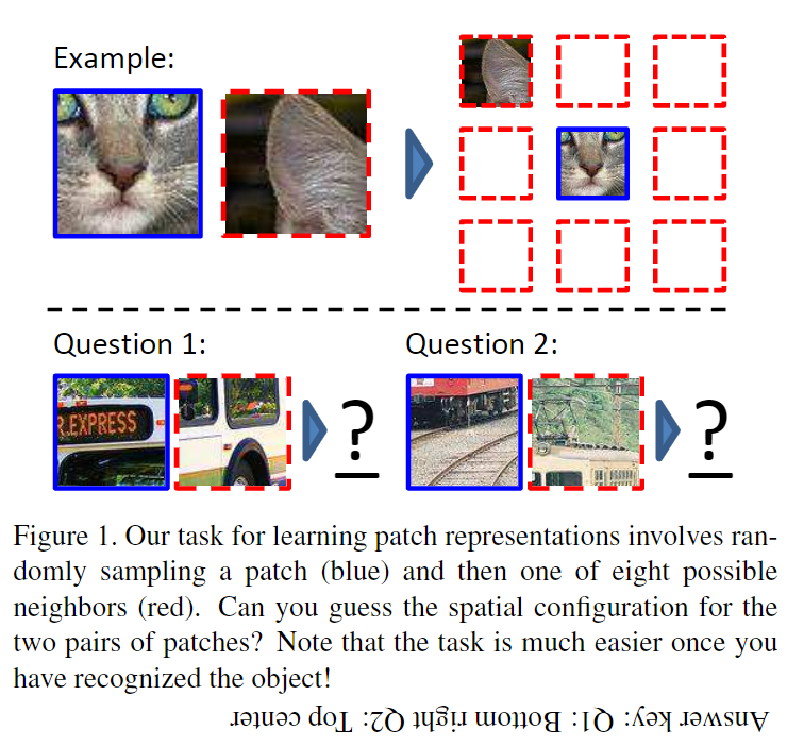
contrastive learning
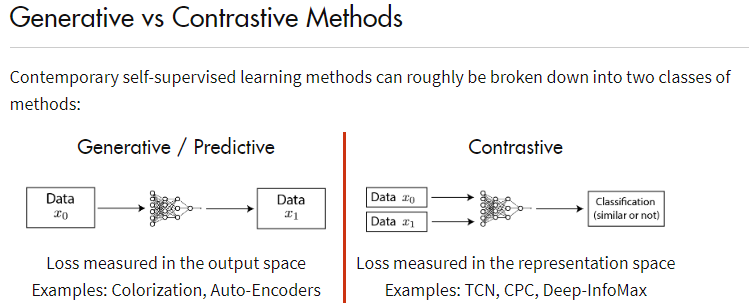
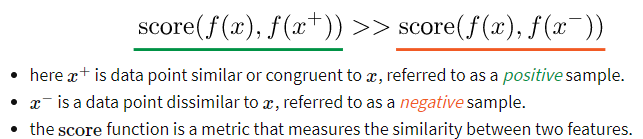
2. Self-supervised learning pretext tasks for EEG
本文描述三种SSL 构造辅助任务的方法
2.1 Relative positioning
对于多变量时间序列$S\in \R^{CM}$, $M$表示序列长度(采样点个数),$C$表示维度(channel),用相同大小的滑窗$(xt,x{t^{,}})$进行截取长度为$T$的片段,$xt,x{t^{,}}\in \R^{CT} $令第一个滑窗为anchor window, 假设时间片相近的片段应该共享同样的标签。 例如,针对睡眠阶段分类,睡眠阶段通常持续1到40分钟;因此,相近的窗口可能来自同一睡眠阶段,而相距遥远的窗口则可能来自不同的睡眠阶段。给定一个持续时间的阈值$\tau{pos}\in N,\tau{neg}\in N$,$y_i$为该分段的标签,对序列进行采样,于是有:
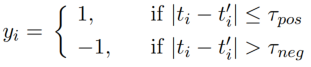
即采样得到的一堆时间片相距小于$\tau{pos}$还是大于$\tau{neg}$
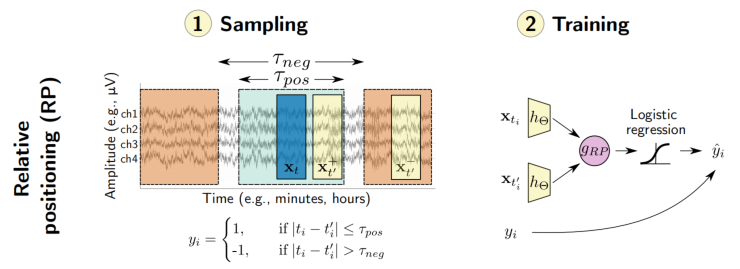
为了学习端到端如何根据时间窗口的相对位置来区分对,我们引入了两个函数hΘ和$g{RP}$。$hΘ:R^{C×T}→R^{D}$是一种具有参数Θ的的特征提取器,它将窗口x映射到特征空间中的表示。 最终,我们期望hΘ学会一个 原始脑电输入的信息表示,可在不同的下游任务中重用。
$g{RP}:R^D×R^D→R^D$通过计算逐个元素绝对差,将来自窗口对的表示结合起来,$g{RP}(hΘ(x),hΘ(x^{,}))=|hΘ(x))-hΘ(x^{,})|\in R^D$。在$g{RP}$将$hΘ$在两个输入窗口上提取的特征向量聚合起来,并突出它们的差异,以简化对比任务。 最后,建立了线性判别模型预测相关的目标y。 利用二元逻辑损失对$g{RP}$的预测,我们可以写出联合损失函数$L(Θ,w,w_0),y$是sign函数。
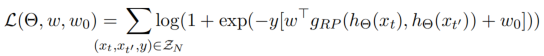
2.2 Temporal shuffling
我们还介绍了RP任务的一个变体,我们称之为Temporal shuffling,其中我们从正例上下文中采样了两个anchor窗口$xt$和$x{t^{‘’}}$,以及第三个窗口$x_{t^{,}}$ ,若在两个正例之间(视为orderd),若在负例范围之内(视为shuffled)。

2.3 Contrastive predictive coding(CPC)
CPC通过编码信息来学习表示法
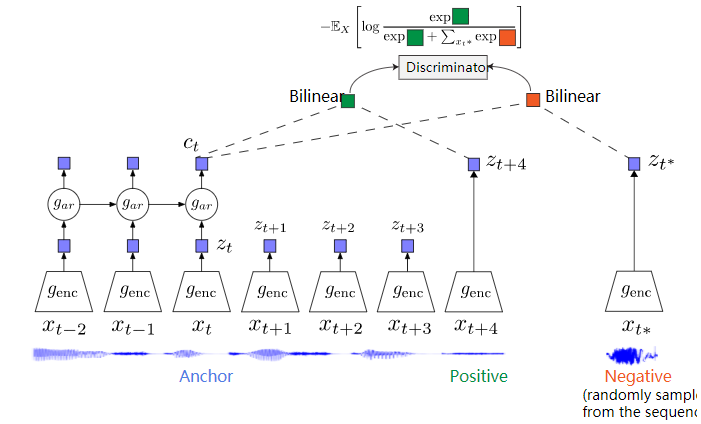
事实上,CPC可以看作是RP的扩展,其中单个anchor窗口$xt$被一系列$N_c$不重叠窗口所取代.这样,上下文中的信息可以用一个向量$c_t∈R^{D{AR}}$表示。 例如,$g_{AR}$可以作为具有门控经常单元(GRU)的递归神经网络来实现)。
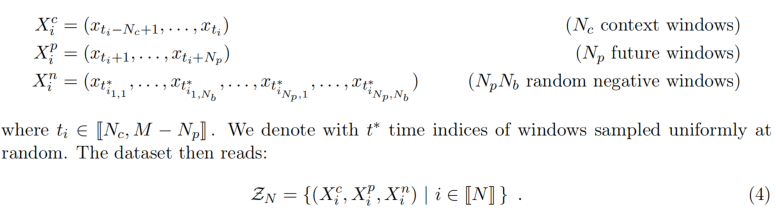
整个CPC模型采用定义为的InfoNCE loss (categorical cross-entropy loss)进行端到端训练。 我们的任务是使context与正例相似度越大越好,与负例相似度越小越好。$f$用来度量context与得到的表示$h_{\theta}$之间的相似度。
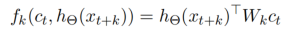
infoNCE定义为:
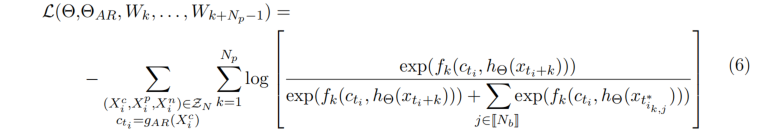
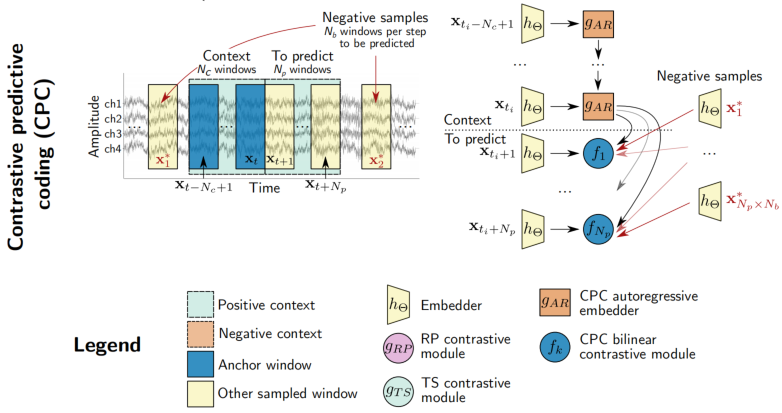
3. Downstream Tasks
我们对两个临床问题进行了基于脑电的SSL的训练,睡眠监测和病理筛查。 这两个临床问题通常导致分类任务,尽管不同的类别和不同的数据生成机制:睡眠监测是关注的 生物学事件(事件水平),而病理筛查与单一患者相比(个体水平)。 为了能够与监督方法进行公平的比较,我们在Physionet2018, 和TUH异常脑电图数据集进行。
首先,对于睡眠分阶任务,目前存在几个局限:1)专家评分存在局限(不准);2)人工标注费时费力。睡眠分期通常会引起5个分类问题,W(清醒),N1, N2, N3(不同的睡眠水平)和R(快速眼动期)。在这里,这项任务包括预测睡眠阶段,对应于30秒的脑电图。
第二,对于病理检测任务,通常需要依赖于非常专业的诊断,如癫痫、痴呆等。在TUH数据集中,医学专家将记录标记为病理或非病理,这导致了二值分类问题。重要的是,这两种标签反映了高度异质的情况:病理记录可以反映由于各种医疗条件造成的异常。
4. Deep learning architectures
我们在实验中使用了两种不同的深度学习体系结构作为嵌入器$h_Θ$获得embedding,如下图。 这两种结构都是由空间卷积和时间卷积层组成,分别学习典型的脑电处理流程中的空间和时间滤波操作。
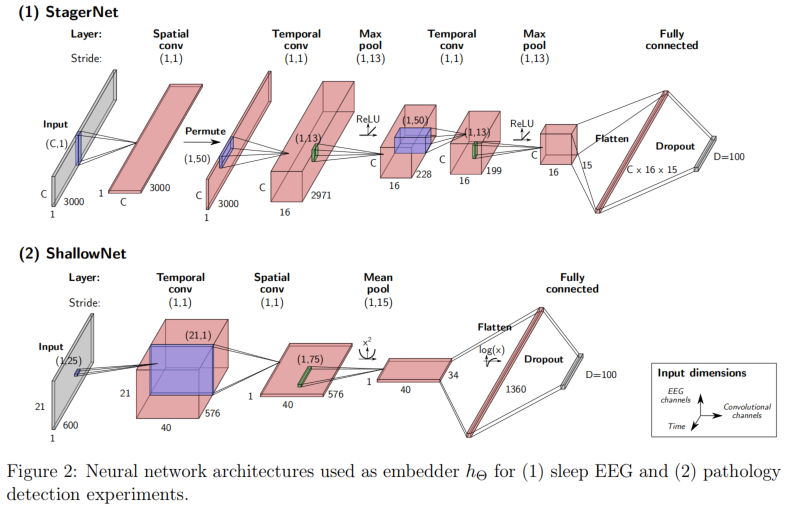
第一个网络叫StagerNet, 是一种三层卷积神经网络,用于处理30s多通道脑电波窗口。
第二种嵌入器结构叫ShallowNet,直接取自以前关于TUH异常数据集的文献。
另外,我们使用一个GRU,隐藏层的大小$D{AR}=100$的CPC任务的$g{AR}$,用于两个数据集上的实验。
5. Experiment
5.1 Data
Physionet Challenge 2018 dataset(PC18)
Recording number: 994;
Sample rate: 200Hz
Channel: 6
TUH Abnormal EEG dataset
这个数据集包含来自在医院环境下接受临床脑电图的2329名不同患者的15分钟或更长的记录。 每个记录都被标记为“正常”(1385次记录)或“异常”(998次记录)。
Sample rate: 256Hz
Preprocessing
对于PC18,我们使用了6:2:2的随机分割,这意味着在训练、验证和测试集中分别有595、199和199条记录。 对于RP和TS,2000对或三重窗口 从每个录音中取样。 对于CPC,从每个记录中提取的批次数被计算为该记录中窗口数的0.05倍;此外,我们将批处理大小设置32
PC18: 降采样成100Hz,只选用两个channel( F3-M2, F4-M1), 1个滑窗大小30s,输入(3000*2)
TUHab:降采样成100Hz,选用21个channel, 1个滑窗大小6s,输入(600*21)
5.2 Baseline
(1) random weights, ( 随机权重,使用一个嵌入器,其权重在随机初始化后保持不变)
(2) convolutional autoencoders,
(3) purely supervised learning
(4) handcrafted features(传统机器学习提取手工特征):均值、方差、偏度、峰度、标准差、(0.5、4.5、8.5、11.5、15.5、30)Hz之间的频率对数功率带及其所有可能的比值、peak-to-peak幅值……
5.3 Results
首先,将SSL方法与基于深度学习或手工制作特性的完全监督方法进行了比较。
其次,我们探索了SSL学习的表示来突出临床相关的结构。
最后,研究了在辅助任务和下游任务中,超参选择的影响。
5.3.1 SSL模型学习脑电图的表示,并利用有限的注释数据促进下游任务
通过在标记示例上训练线性Logistic回归模型来评估下游任务性能,其中训练集至少包含一个和最多包含所有现有标记示例。 此外,完全监督的模型直接在标记数据上进行训练,随机森林在手工制作的特征上进行训练。标记样品数量对下游性能的影响如下图所示:
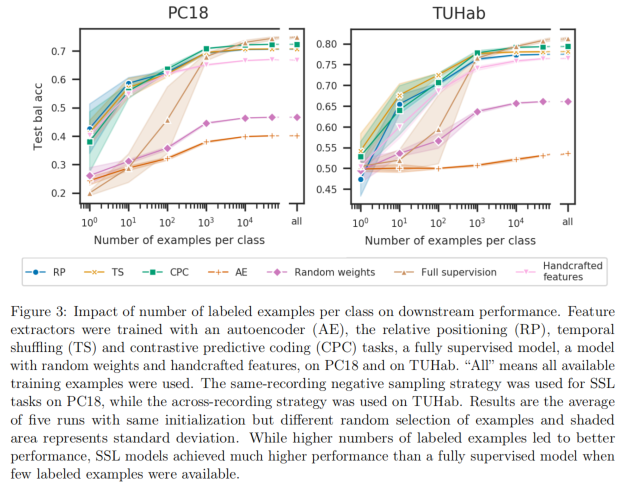
PC18 72.3% balanced accuracy(5-class,chance=20%)
- 标签少时:RP/CPC/TS/Handcrafted feature 显著优于 full-supervision/AE/Random weights
- 标签增多:full-supervised得到显著提高,RP/CPC/TS/Handcrafted feature依然较好
TUHab 79.4% (2-class, chance=50%)
- 总体趋势与第一个数据集表现类似
- 每个类标签少于10000时,监督方法弱于CPC
这些结果证明了SSL能够为我们的下游任务学习有用的表示。 其次,比较表明SSL学习的特性与其他基线相比具有竞争力,甚至可以优于监督的方法。
5.3.2 SSL models capture physiologically and clinically meaningful features
虽然SSL学习的特性在睡眠分期和病理检测任务上产生了竞争性能,但尚不清楚SSL捕获了什么样的结构。
通过分析它们与临床数据集中可用的不同注释和元数据的关系来观察这种嵌入之间的关系。 因此,我们将在PC18和TUHab上获得的100维嵌入投影到一个二维表示上,使用均匀流形近似和投影(UMAP)并使用表现最好的模型。
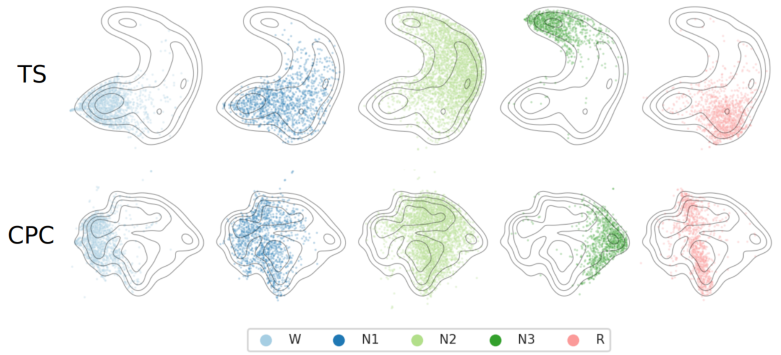
PC18数据集上SSL特性的UMAP可视化。 子图显示了5个睡眠阶段的分布,作为TS(第一行)和CPC(第二行)特征的散点图。 轮廓线对应所有阶段的分布密度水平,用作视觉参考。 最后,每个点对应于从脑电图的30s窗口提取的特征。 在这两种情况下, 有明确的结构与睡眠阶段,虽然在训练期间没有提供标签。
我们认为,ssl学习特征的连续性质是所研究的神经生理现象所固有的。方便的是,这为改善生理数据的分析提供了机会。
5.3.3 SSL pretext task hyperparameters strongly inflfluence downstream task performance
在临床脑电图任务中,如何调整各种SSL辅助任务的超参数以充分发挥自我监督的作用?
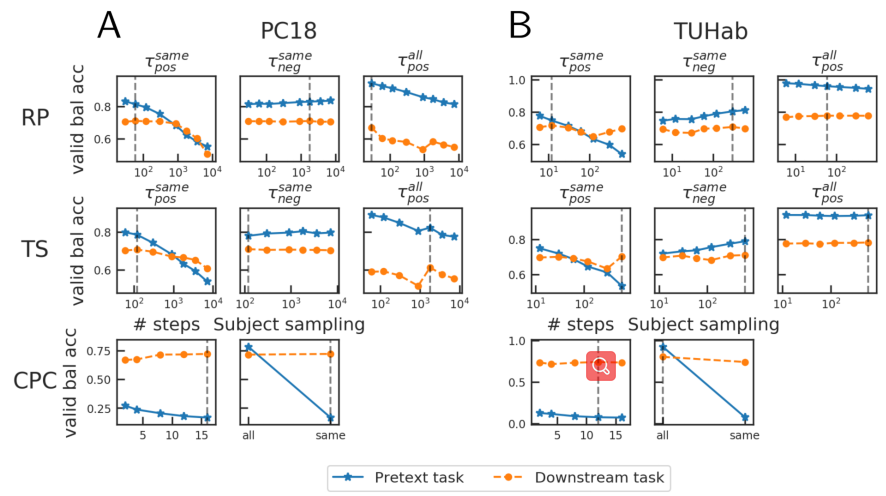
首先,我们重点讨论了相同记录的负采样场景,其中从与anchor窗口相同的记录中采样负示例。 对于RP,随着$τ{pos}$的增加,总是使辅助任务分类更难。 这是预料中的,因为给定是$\tau{pos}$的时间(上下文)越大,就越有可能得到由遥远的(因此可能不相关的)的正例对。
至于CPC,一项类似的分析表明,虽然增加了预测窗口的数量(“步数”),使辅助任务变得更加困难,但预测未来的进一步发展有助于预测,嵌入器学习更好的睡眠分期表示
在这个实验中,我们证实了我们的SSL辅助任务并是对下游任务是有影响的,并且某些辅助任务超参数对下游性能有可测量的影响。
6 Discussion
6.1 Finding the right pretext task for EEG
随着人们所能想到的大量自我监督的借口任务,以及更多可能的脑电下游任务,我们如何选择辅助任务和超参数组合?
我们引入并定制了相对定位(RP)和时间片打乱(TS)任务,依靠对脑电的先验知识。 事实上,睡眠脑电图信号具有明确的时间结构,起源于夜间睡眠阶段的连续。这意味着在时间上相近的两个窗口很可能共享相同的睡眠阶段注释和统计结构。因此,学习区分近窗和远窗应该与学习区分睡眠阶段有直观的关系。
选择辅助任务超参数对于选择正确的辅助任务配置至关重要。 例如,RP、TS和CPC通常产生非常相似的下游任务。 一旦选择了最佳的超参数,就可以进行性能测试。
6.2 Limitation
本工作的目的是引入自我监督作为脑电的一种表征学习范式,我们没有关注这两类任务与早期工作中的最先进性能的表现。
7. Conclusion
在本工作中,我们引入了SSL方法来学习EEG数据上的表示,并表明它们可以与两个大型临床数据集上的传统监督方法竞争,有时甚至优于传统的监督方法。 重要的是,SSL学习到的特征显示了一个清晰的结构,其中不同的生理量被编码,这验证了自监督学习的潜力,以捕捉重要的生理信息,即使在没有标记的数据。 未来的工作将分为以下两方面:
- 证明SSL是否也可以成功地使用于其他类型的脑电图记录和任务中,如回归。
- 更好地理解如何为特定的脑电图结构设计辅助任务,对于利用自我监督学习建立作为脑电图分析流程的关键组成部分至关重要。