Proc. VLDB Endow. 13(8): 1176-1189 (2020)

摘要
随着云数据库市场的不断增长,检测和消除慢速查询对服务稳定性至关重要。以前的研究集中在优化由于内部原因(例如,编写得不好的sql)而导致的缓慢查询。
在这项工作中,我们发现了一组不同的慢速查询,与其他慢速查询相比,这些查询对数据库用户的危害可能更大。我们将这种查询命名为间歇性慢速查询(iSQs),因为它们通常是由外部的间歇性性能问题造成的(例如,在数据库或机器级别)。诊断iSQs的根本原因是一项艰巨但非常有价值的任务。
本文提出iSQUAD(Intermittent Slow QUery Anomaly Diagnoser),一个可以诊断iSQs的根本原因的框架,它对人工干预的需求比较松。
面临的挑战:通用性、标签开销和可解释性。因此设计了四个组件:
- 异常提取
- 依赖清理
- 面向类型的模式集成聚类(TOPIC)
- 贝叶斯实例模型(Bayesian Case Model)
组成:
- 阶段一:离线聚类+解释
- 阶段二:在线跟因诊断+更新
数据集:阿里巴巴OLTP数据库的真实数据集
介绍
云数据库正在不断地发展,数据库中的服务中断或性能故障可能会导致严重的效率损失和品牌损失。因此,数据库总是处于不断的监控之中,检测和消除慢速查询对于服务的稳定性至关重要。
大多数数据库系统,如MySQL、Oracle、SQL Server,会自动记录完成时间超过用户限制阈值的查询的详细信息。一些缓慢的查询是由内部原因造成的,比如复杂性、缺乏索引和SQL语句编写得很差,这些可以被自动分析和优化。
间歇性慢速查询(iSQs):这些慢速查询是由外部的间歇性性能问题(例如,在数据库或机器级别)导致的。
造成损失严重,手动诊断费事费力
通常,iSQs是云数据库中性能问题甚至故障的主要症状。由于iSQs是断断续续的,服务开发人员和客户希望它们能够正常响应,而突然增加的延迟会产生巨大的影响。例如,在浏览网页时,iSQ可能导致网页加载延迟。据报道,亚马逊每0.1秒的加载延迟就会损失1%的销售额,而谷歌搜索结果每0.5秒的加载延迟就会导致的流量下降20%。我们获得了阿里巴巴OLTP数据库的数据库管理员在一年内注意到的几个性能问题记录:当一个性能问题发生时,一系列的isq持续几分钟。事实上,手动诊断iSQs的根本原因需要几十分钟,这既费时又容易出错。
本文的工作目标:尽可能的减少人工干预来进行于数据库中iSQ的跟因诊断。以下是观察到的异常症状和跟因的一些记录:
- 数据库管理员需要扫描数百个关键性能指标来查找性能问题症状。
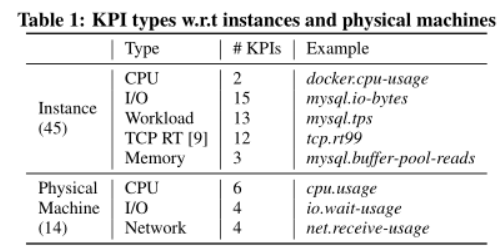
性能问题异常主要包括不同的kpi模式。我们总结了三组对称的KPI模式,即,突起突降,水平漂移(向上或向下),缺失。单纯基于检测KPI异常与否,我们无法准确诊断iSQs的根本原因。
一个异常KPI通常伴随着另一个或多个异常KPI。
类似的异常与相同的根因相关。在每个根本原因类别中,性能问题的KPI症状彼此相似。
提出iSQUAD(Intermittent Slow QUery Anomaly Diagnoser),其中,我们采用异常提取和依赖清理来代替传统的异常检测方法,以解决异常多样性的挑战。为了减少标记开销,提出了面向类型的模式集成聚类(TOPIC),将具有相同根源的iSQ聚类在一起,同时考虑KPI和异常类型。在聚类可解释性方面,利用贝叶斯实例模型为每个聚类提取基于实例的表示,便于DBAs研究。
组成:
阶段一:离线聚类+解释
获得聚类和跟因,用于在线阶段的诊断。数据库管理员只需要对每个聚类标记一次,除非在线阶段出现了新的类。
阶段二:在线跟因诊断+更新
工作主要贡献:
基于云数据库中iSQs速度慢的问题,并设计了一个名为iSQUAD的可伸缩框架,该框架可以为iSQs提供准确而有效的根因诊断。它采用了机器学习技术,克服了在通用性、标识开销和可交互性等方面的挑战。
异常提取:使用KPIs的异常提取来代替异常检测来区分异常类型。
聚类:提出了一种新的聚类算法TOPIC来减少标记开销。
最先通过贝叶斯实例模型在数据库领域中应用和改进基于实例的推理,并将实例子空间表示推给DBAs用于标记。
我们对iSQUAD的评估进行了大量的实验,证明了我们的方法获得了平均F1-score 80.4%,较前一种技术提高了49.2%。此外,已经在真实的云数据库服务中部署了iSQUAD的原型。iSQUAD可以帮助DBAs在80分钟内找到数百个iSQs的全部10个根因,这比传统的逐例诊断快大约30倍。
背景与动机
背景
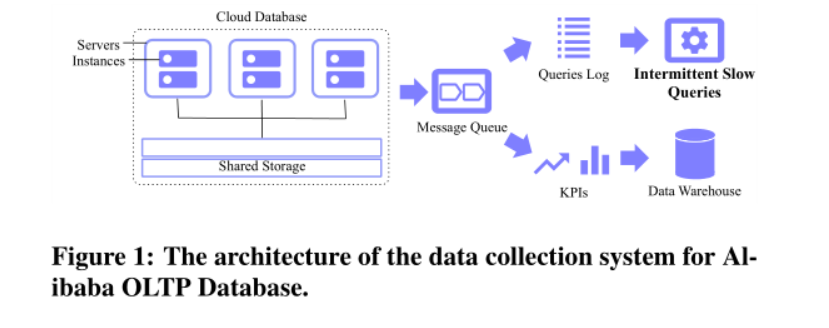
阿里巴巴OLTP数据库
支持的服务有淘宝、天猫、钉钉和菜鸟等。这个数据库包含了跨越几十个地理区域的十万个实际运行的实体,配备有一个度量系统用于收集日志和KPIs。
Intermittent Slow Queries (iSQs)
查询时间:SQL查询被提交给数据库和其结果被数据库返回之间的时间。
iSQ:第$t$ 个SQL语句 $Q_t$,执行时间$X_t$,当$X_t>z$且$P(X_i>z)<\epsilon$,其中$1<=t,i<=T$,z是一个iSQ的阈值。对于阿里数据库管理员设置:$z=1s,\epsilon=0.01,T=10^4$
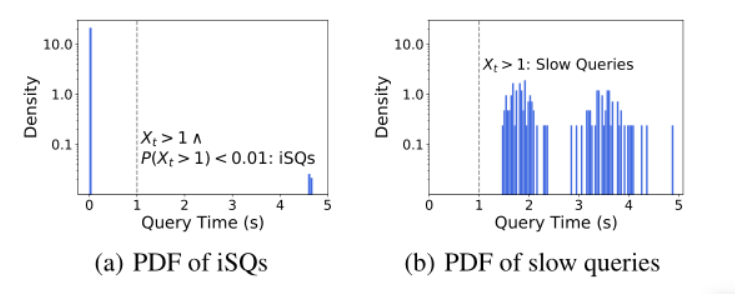
图(a) 每条语句查询时间的概率分布,iSQs的占比0.0028
图(b) 每条语句查询时间的概率分布,每条SQL语句都比较慢
在慢速查询中,其他类型的慢速查询主要是由任务的复杂性造成的,通常是非交互和可容忍的(约占79%),这些慢速查询可以通过添加索引或重写SQL语句等方式来进行优化。
iSQs只占1%,但其影响非常大,比例很小,但是每天都会是成千上万的,处理优化这些异常有利于调高用户体验。
观察
由于当出现性能问题时,许多正常的在线服务查询会受到影响,速度会比平时慢得多,所以,理解iSQs的根本原因对于缓解慢速查询很重要。
(需要多变量)KPIs对于定位iSQs的根本原因非常重要。单独的KPI不能捕获所有类型的问题,不同类型的KPI才能掌握跟踪整个系统的状态。
(以前的工作并没有关注异常类型,仅关注是否异常)应该注意kpi的异常类型。
突起突降、水平漂移(向上或向下)、无效(缺失或为0)
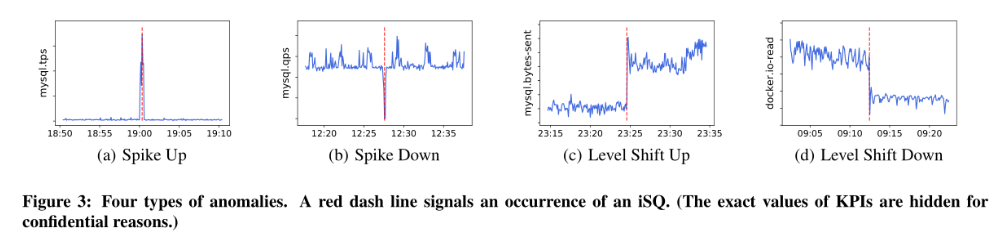
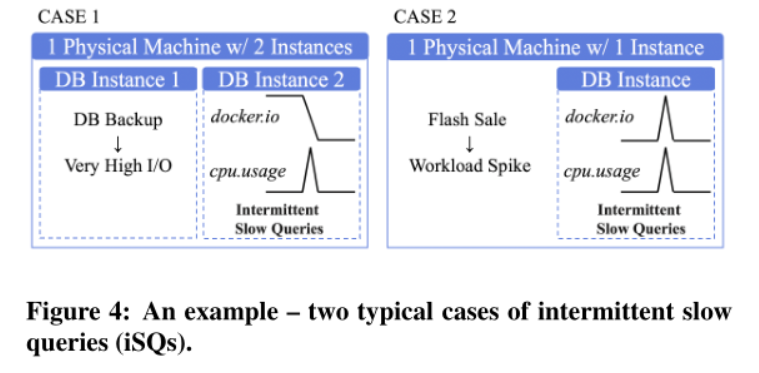
异常类型与异常跟因有关
case1 实例1进行数据库备份,两个实例共享IO
case2 只有一个物理机器,发生总体工作负载增加(闪购时间)
(序列之间的相关性、依赖性)KPIs间异常是高度相关的,其关系可能是单向,也可能双向。
类似的KPI模式与相同的根本原因相关。
例:DBAs将异常跟因分为了10类,每种跟因中,有些KPI异常是相似的,可以相互替换,比如 sql-update和sql-delete引起的负载异常。
挑战
- 异常类型多样性
之前的方法的局限性:目前的异常研究普遍忽略和过度概括了异常类型。这样的检测方法可能会在(监控数据)预处理阶段错误地检测出大量信息,从而降低(监控)数据集的质量。
- 标签开销大:专家工作量大、过程复杂
之前的方法的局限性:有复现跟因的方法——实际情况不允许;自定义数据负载进行统计也是不现实的(?)
- 可解释的模型:模型的准确性和它对人类的可解释性之间存在不可避免的权衡。
之前的方法的局限性:决策树,依赖于开始时提供精确的信息,因为即使是输入中的细微差别也可能导致大的树修改,此外,决策树还可能产生“分析瘫痪”的问题,即向决策者提供的信息过多,而不是关键要素。
概览
模型框架:iSQUAD (Intermittent Slow QUery Anomaly Diagnoser)
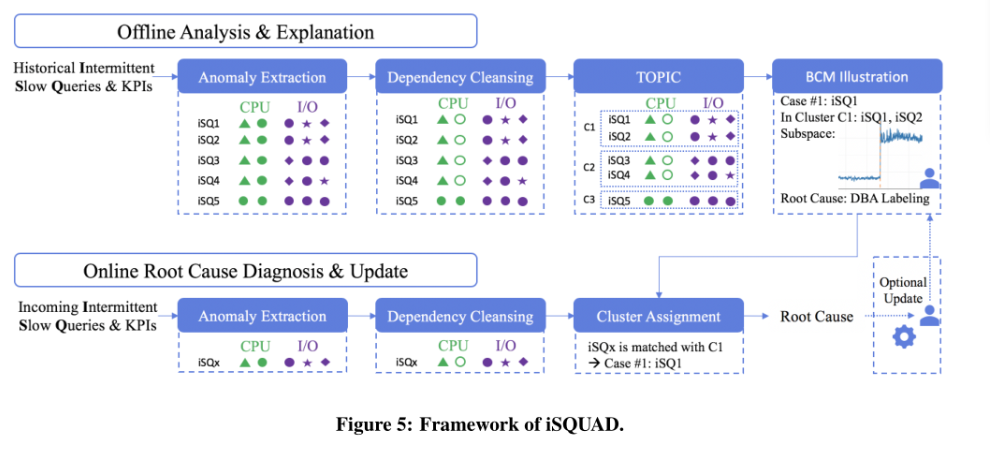
离线阶段:对iSQs进行聚类,让专家更容易的识别标记跟因。
异常提取—异常KPIs离散化—依赖清理—聚类—Bayesian Case Model(一个典型的iSQ和它的基本KPI矩阵作为特征空间)
在线阶段:输入iSQ和其对应的KPIs—异常提取—异常KPIs离散化—依赖清理—查询匹配一个跟因类—给DBAs展示解释异常(若未匹配,则分配到一个新类)
iSQUAD细节设计
离线阶段:异常提取
峰值:Robust Threshold(中位数和中位数绝对偏差值)(假设是柯西分布),时间间隔1h,阈值根据经验。
水平漂移:分成两个窗口,检验两个窗口分布是否相似,如果通过T-Test(一种用于测试两组平均差异的推断统计量)发现存在明显差异,则确定发生水平飘移。窗口30分钟,t值根据经验。
离线阶段:依赖清理
目的:确保KPIs之间相互独立,这样就没有相关性或者过度表示。
相关指数(阈值):
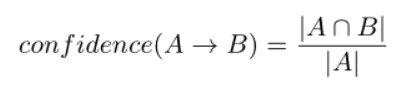
例子:CPU(实体和物理机器)
离线阶段:面向类型的模式集成聚类(Type-Oriented Pattern Integration Clustering,TOPIC)
pattern:一个iSQ的封装的KPI特定组合

两个iSQs之间的相似度: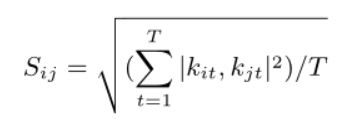 t是KPI类型数目,T是总KPI类型数目
t是KPI类型数目,T是总KPI类型数目


离线阶段:Bayesian Case Model 贝叶斯实例模型
作用:从每个聚类中提取有用的和有启发性的信息,为DBAs打标签提供便利
前提:离散化 标签(聚类的结果)
在线阶段:跟因检测和更新
匹配:相似度最高的一个模式
更新:匹配失败后,交给DBAs处理
评估
设置
iSQs数据集 阿里OLTP数据集(随机的,一个任意一天的数据集 两个 周数据集)(一个实体上的每个时间戳只选一个iSQ)
KPIs数据集 发生在iSQ前后一小时的数据,粒度5秒
人工标记标记 (DBAs)
- 三个数据集上随机选取319个iSQs标记跟因
评估分数
- F1-Score
- Weighted Average F1-score
- Clustering Accuracy
- Normalized Mutual Information (归一化互信息)
iSQUAD的准确性和效率
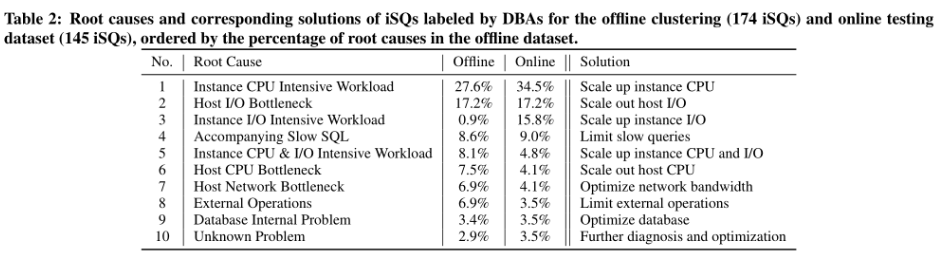
设置:对174个iSQs进行聚类,得到10个聚类,对剩下145进行测试
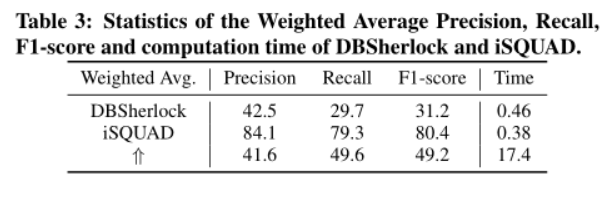
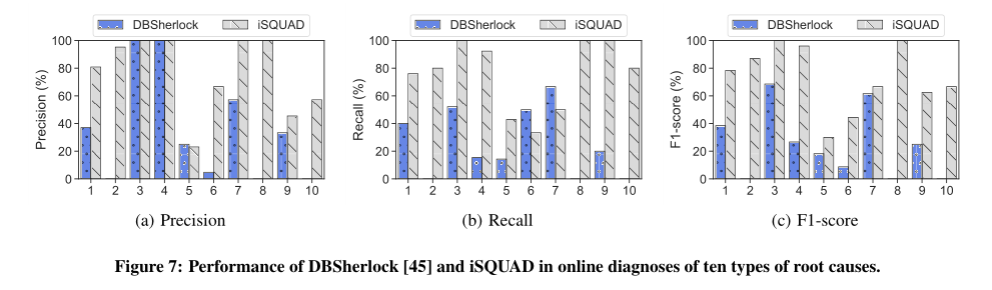
iSQUAD在四个方面优于DBSherlock
1)DBSherlock需要用户自定义或自动生成KPI的异常和正常间隔。其旨在解释异常间隔,而非时间戳
2)DBSherlock根据平均值的差异是否超过一个阈值来区分两个部分,iSQUAD具有利用不同波动的异常提取功能
3)DBSherlock不能消除KPIs之间的依赖关系
4)DBSherlock利用因果模型提供纯文本解释不同,忽略了一部分异常类型和模式;iSQUAD使用了贝叶斯实例模型,以向DBAs显示可理解的实例子空间表示。
异常提取的性能
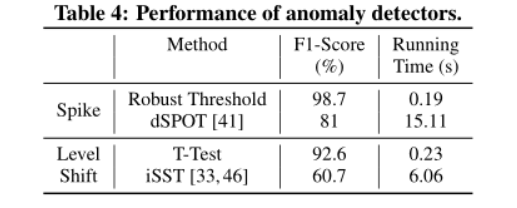
时间计算:执行一个iSQ
性能优的原因:包容性和通用性
依赖清理精度
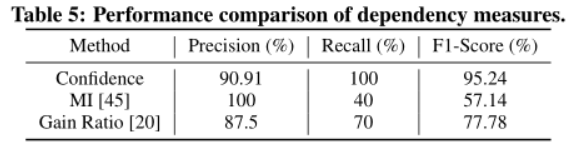
TOPIC评估
层次聚类容易产生离群值效应,新模式的iSQ会被归类为离群值,而非新的一类。层次聚类需要预先设定聚类中心的个数。
K-means集群也需要预先限定的集群数量。此外,它高度依赖于初始iSQ模式,因此不稳定。
DBSCAN产生的集群是严重倾斜和分散
BCM评估
BCM的影响:使用了iSQUAD后,减少了DBAs需要考虑的KPIs数量。减少诊断时间,是以前的30倍。
可视化平台:将贝叶斯实例模型嵌入可视化平台中,该可视化平台可以显示iSQ类的实例子空间表示及其跟因。在DBA选择iSQ类之后,该平台会立即显示相应的KPI,并输出这个iSQ类的根因。
用户研究
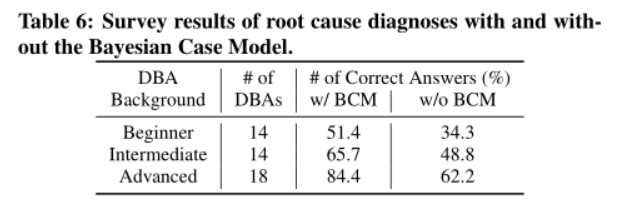
案例及讨论

人工:18min
框架:40s
多跟因:1)挖掘更深层次的原因 2)多跟因的发生概率很小
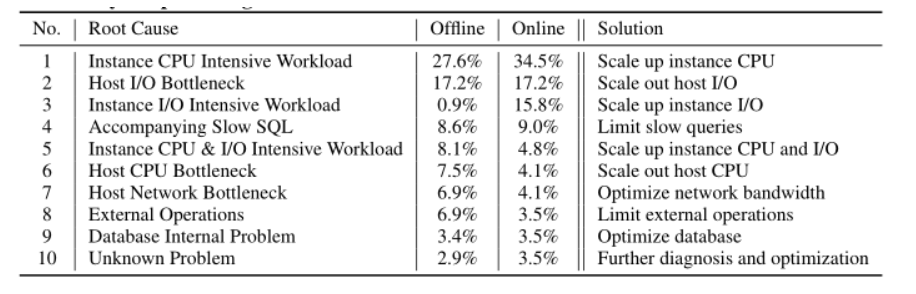
iSQUAD的普遍性 很多场景适用
对不同原因的操作
(1)Scaling(#1,#2,#3,#5,#6):增大资源
(2)Limiting (#4, #8):限制速率
(3)Optimizing (#7, #9, #10)
相关工作
Slow Query Analysis
自动化索引修改、机器学习算法调优数据库参数、深度学习提升查询
Anomaly Extraction
二分类(即异常、正常)的异常检测方法:
Opprentice
dSPOT
iSST
雅虎的EGADS
推特的S-H-ESD
Netflix的RPCA
Clustering Algorithm
Root Cause Diagnosis
未来工作
作为未来的工作,我们的目标是在iSQUAD的基础上开发一个更通用的、更有能力的框架,自动化故障诊断和系统恢复。