[INFOCOM2021]
摘要
本文提出了一个基于粗到细模型迁移的CTF框架,以实现可扩展和准确的数据中心规模的异常检测。CTF预先训练一个粗粒度模型,使用该模型提取每台机器的特征并计算其分布,根据分布对机器进行聚类,并进行模型迁移以对每个类簇模型进行微调以获得较高的精度。文中还对聚类算法、距离度量等设计进行了证明,以达到最佳的精度,并在生产数据上进行实验,验证了其可扩展性和准确性。
关键字:异常检测,高维,时间序列,大规模
介绍
背景:大规模数据中心的异常检测监控
挑战
1 基于深度学习的算法面临的挑战:维度爆炸
- 机器数量
- 检测指标数量(KPI)
- 时间粒度细(30s)
对于每个机器构建一个模型,能够确保精确度,但是不能保证效率
因此提出,先对机器进行聚类,对每一类的机器使用一个模型。
2 引出另一个挑战:直接对机器的高维KPI进行聚类,会由于高维引起的维度灾难,带来计算效率低的问题
因此提出,对高维KPI做一个降维表示
进一步构建框架的挑战
1 RNN-VAE模型的训练和聚类之间存在依赖关系
要聚类的前提是有训练好的模型获得低维潜在表示,但训练一个RNN-VAE模型只用没聚类的高维时间序列数据很难准确且高效
解决办法:提出一个 coarse-to-fine model transfer framework
2 time domain : 潜在表示仍然是高维时间序列
这样对聚类很不友好
解决办法:将时间序列转换成分布,这既提高了效率,也提高了准确性
3 要对模型迁移策略、聚类算法、距离度量进行选择
框架:CTF
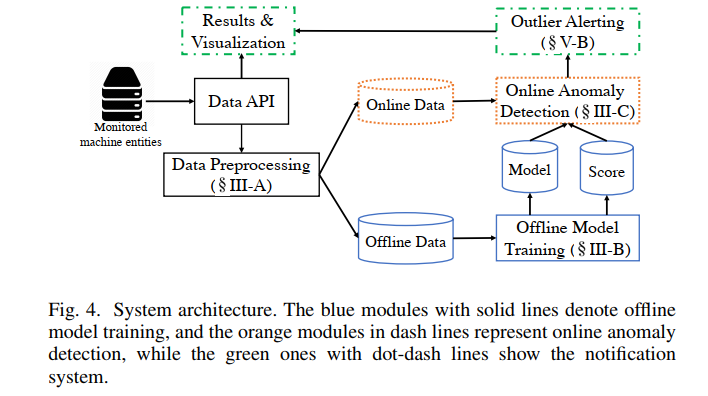
离线训练分为四步:
- 采样部分数据训练粗粒度模型
- 使用粗粒度模型将每台机器的多变量时序转化为低维潜在表示
- 基于潜在表示的分布对机器进行聚类
- 对每个聚类的机器fine-tune模型
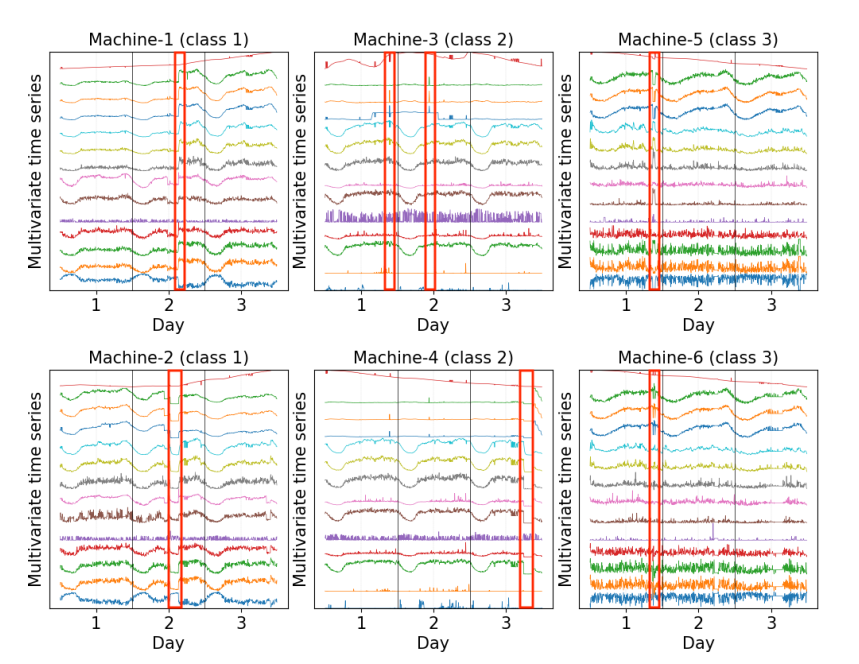
我们的评估表明,当CTF使用OmniAnomaly算法,CTF可以将模型训练时间从两个月左右减少到4.40小时(6台计算服务器,一个数据中心10万台机器),F1score-0.830(loss0.012)
贡献
我们提出了一个基于coarse-to-fine model transfer 的框架,该框架可以在机器、KPI和时间域上具有高维的庞大操作数据集上执行异常检测。其核心技术如下:
- 第一次综合了模型训练和机器聚类,并对两者进行了加速;
- 第一次利用潜在表示的分布进行聚类,加速了对距离的计算;
- 第一次对RNN-VAE模型应用微调策略,验证其在准确性和效率方面的好处;
在全球顶级互联网公司的大规模数据集上使用最先进的异常检测算法对CTF进行了实现和评估,展示了CTF在实际基础设施中的有效性和可扩展性。
- 开源了多变量时间序列的标记工具和标记的数据集
背景
问题陈述

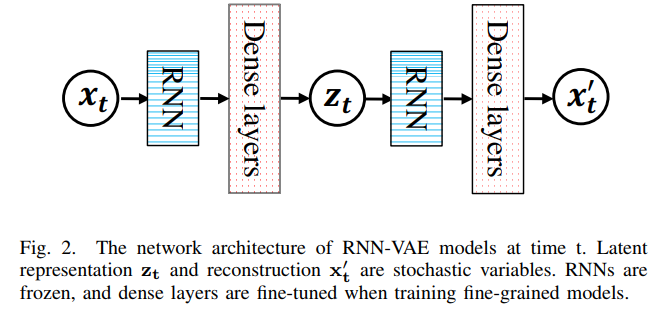
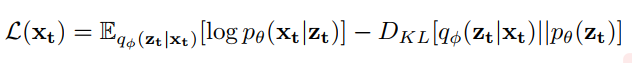
动机:我们观察到基于RNN-VAE的算法可以利用VAE的典型结构将每个高维KPI向量(L)压缩为低维潜在表示(C)。
挑战
- 聚类与模型训练之间的相互依赖性
解决:(1)先采样部分数据,对粗粒度模型进行预训练;(2)使用粗粒度模型将每台机器的MTS转换为潜在表示;(3)利用潜在表示的分布将机器分类成K个簇;(4)将粗粒度模型迁移到每个类簇,并对每个类簇的细粒度模型进行微调;
聚类算法:Hierarchical Agglomerative Clustering. (HAC)
优点:
- 不需要初始参数(聚类数和距离阈值等)
- 它对距离测量算法不敏感,因为它是基于距离的排序而不是值进行聚类
- 不同层次之间的关系是明显的,便于我们可视化聚类结果
- The high dimension of the time domain
解决:对潜在表示序列进行抽样,得到分布,并在聚类中利用分布进行距离计算。
距离度量:Wasserstein distance
在两个分布之间的重叠较少或没有重叠时特别有用
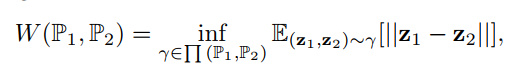
- 神经网络训练方法的选择
在新数据集中训练旧模型的所有神经网络层,在新数据集中训练旧模型的部分层(即微调)
微调dense layers
设计
数据预处理
- 缺失值填充(previously observed value)
- Data normalization
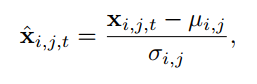
离线模型训练
1)预训练粗粒度模型
2)特征提取
抽取部分KPI进行降维表示,学习分布
3)机器聚类
子集上进行聚类中心计算
4)模型迁移
冻结RNN层
The reason is that RNN layers are shallow and deterministic, and thus, they extract general time-series features in the coarse-grained model, which could contribute to the model generalization
在线检测
异常分数:重构概率(KPI接近normal行为的概率)
阈值选择:Peaks-Over-Threshold (POT)
1)POT对整个群体中某一低分位数以下的样本记性过滤,用Generalized Pareto Distribution (GPD) 拟合,获得GPD函数;
2)利用函数和整个群体中的一个异常分位(q)数来确定阈值
优点:①没对整个总体分布进行假设 ②低分位数和q ③实际效率高
实现
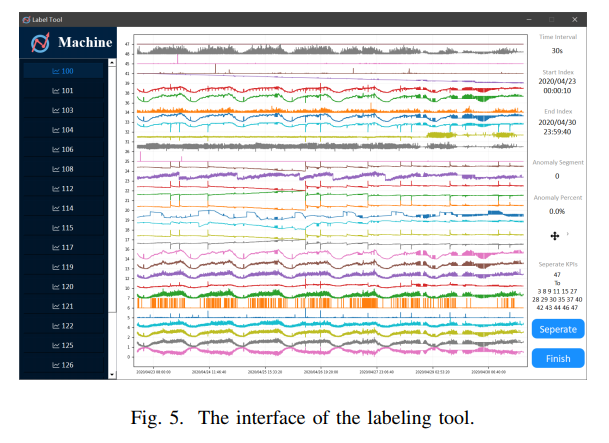
功能
- 加载、可视化、拖动、放大/缩小时间序列,使用户可以概览整个序列的形状,并定位某个片段的细节
- 可以折叠和展开几个KPI维度,为用户提供更好的视图
- 对异常进行标记或取消。用户可以选择间隔的开始和结束,并将其保存为异常
- 实时收集并更新异常间隔(如计数、百分比)的统计信息。
评估
数据集
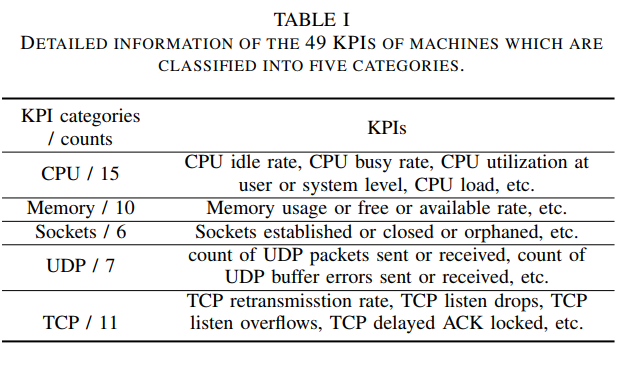
- 533机器实体
- 每个机器49条KPI
- 采样间隔30s
- 13天数据(from April 18th to April 30th)
参数
预训练采样实体数:100
预训练采样KPI数:每个实体的10%
聚类数:5
低分位数:0.01, 0.02, 0.03
q:$10^{-5}$
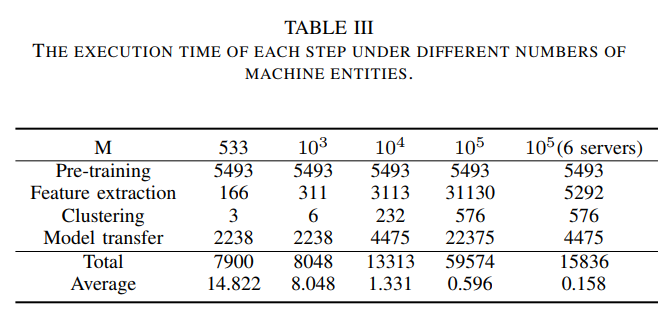
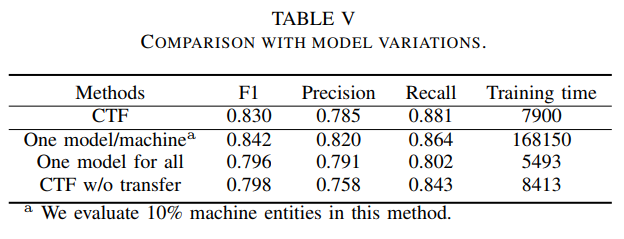
性能
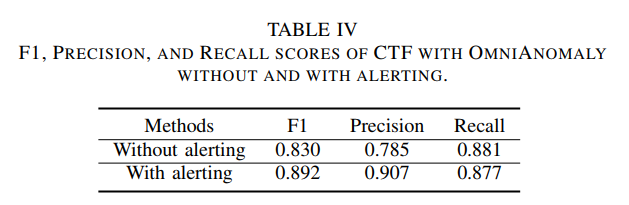
we tune alerting policy cross-time: at least N consecutive anomalous points will be considered as anomalies (e.g., N = 5 in our scenario).
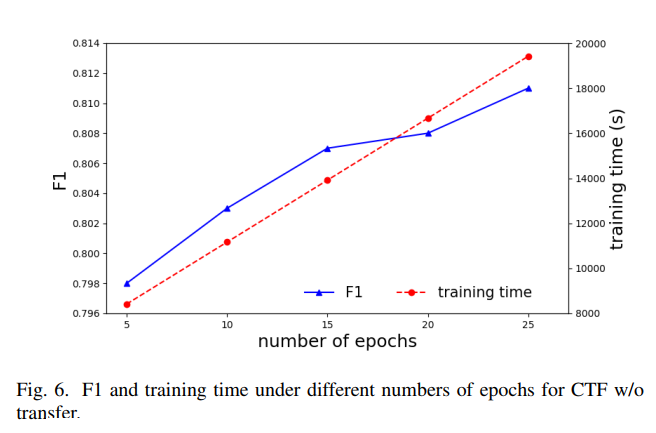
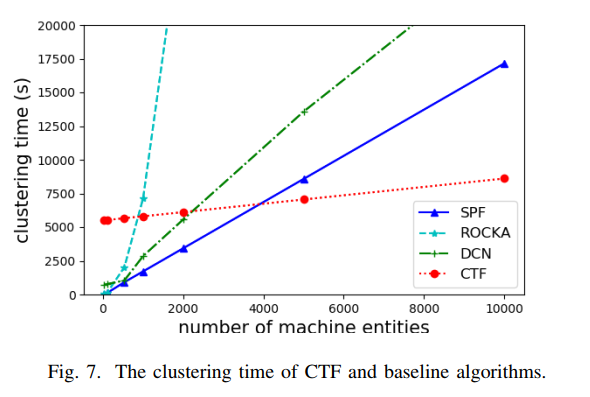
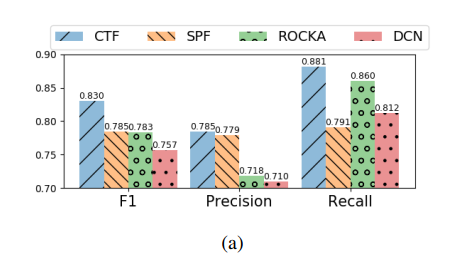
特征表示
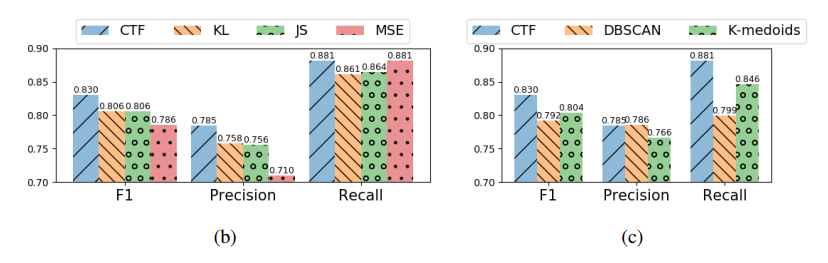
总结
本文提出了一个基于粗到细模型迁移的CTF框架,以实现可扩展和准确的数据中心规模的异常检测,离线模型训练分四步进行,每一步的设计提高精度且提高性能,更是公开了数据集和开源了标签工具。另外,该框架可以扩展到大规模时序预测或分类。