关键词: 元学习;迁移学习
贡献
- 提出了元迁移学习(MTL, Meta-Transfer Learning),该方法学习如何将深度神经网络的权值转移到小样本学习中任务
Meta:指训练多个任务;Transfer:学习每个任务的DNN权重的缩放和偏置(SS, Scale and Shift)来实现迁移 - 其次,提出了Hard Tasks(HT)进一步提高MTL的学习效率
- 在有监督和半监督的环境下,我们在minimagenet、tieredImageNet和Fewshot-CIFAR100(FC100)这三个具有挑战性的基准上对五类小样本分类任务进行了实验,验证了本文提出的HT模式训练的MTL方法具有很好的性能。消融研究表明,SS和HT两个组件有助于快速收敛和高精度。
- 另外,在每个任务上加入元梯度正则化,利用当前任务和前一任务的元梯度加权和对每个任务进行优化。其目的是迫使元学习器在以后的学习中不要忘记旧知识。
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2019,
(由CVPR 2019《Meta-transfer learning for few-shot learning》扩充)
作者:Qianru Sun, Yaoyao Liu, Zhaozheng Chen, Tat-Seng Chua, and Bernt Schiele, Fellow, IEEE
机构:新加坡管理大学、马克斯·普朗克信息研究所、新加坡国立大学
Code: https://github.com/yaoyao-liu/meta-transfer-learning
背景
样本过少的情况下→数据增强 / 元学习→现阶段MAML仍有缺点
- 元学习被应用于小样本学习:关键的想法是利用大量相似的小样本任务来学习如何使基础学习器适应一个新的任务
- 元学习是一种基于任务级优化的方法。其目的是从相似的小样本学习任务中转移经验,相关方法遵循一个包含两个循环的统一训练过程。内循环学习一个基础学习器(base learner)完成一个单独的任务,外循环使用学习基础学习器的验证性能来优化元学习器。
一种先进的代表性方法称为模型不可知元学习(MAML),它学习寻找最佳的初始化状态,使基础学习器可以快速适应新的任务
- i)这些方法通常需要大量类似的元训练任务,成本高昂;
- ii)每个任务通常由一个低复杂度的基础学习器建模,如浅层神经网络(SNN),避免模型过拟合到实拍训练数据,从而无法部署更深入、更强大的体系结构
传统的meta-batch包含许多随机任务,没有考虑不同任务的困难程度。
最近的一些工作尝试使用在大规模数据集上预先训练的DNN,但大多是以直接的方式,例如:①将其权重作为元训练的热启动;②冻结其卷积层作为基础学习器的特征提取器。
方法
总体框架
(a) 在大规模数据上的DNN预训练,即使用整个训练数据集
(b) 在预训练的特征提取器的基础上学习缩放和移位(SS)参数的元转移学习(MTL)
这一步使用 HT meta-batch 进行,并由元梯度正则化(第4.3节)正则化
(c) 是对不可见任务的元测试,其处理包括基本学习器(分类器)的微调(FT)阶段和最终评估阶段
这篇文章里 meta-learner(外层优化) 指的是SS,base-learner(内层优化) 指的是classifier,还包含后期固定的feature extractor。
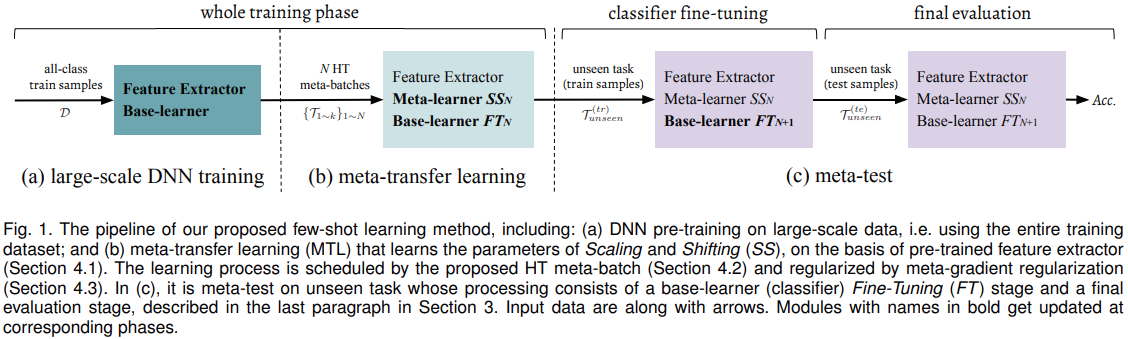
Meta-transfer learning (MTL)
元任务的训练集用来训练基础学习器,基础学习器(分类器)θ’的更新规则:($\Phi_S$是SS的权重)
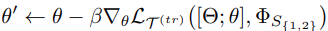
$\Phi{S_1}$初始化为1,$\Phi{S_2}$初始化为0,并按下式更新:
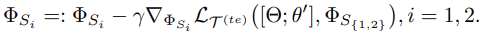
使用元任务的测试机损失及梯度,用于元参数 $\theta$ 的更新:
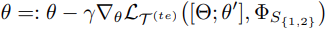
$\Phi_S$是SS的权重,元训练期间冻结不予更新。
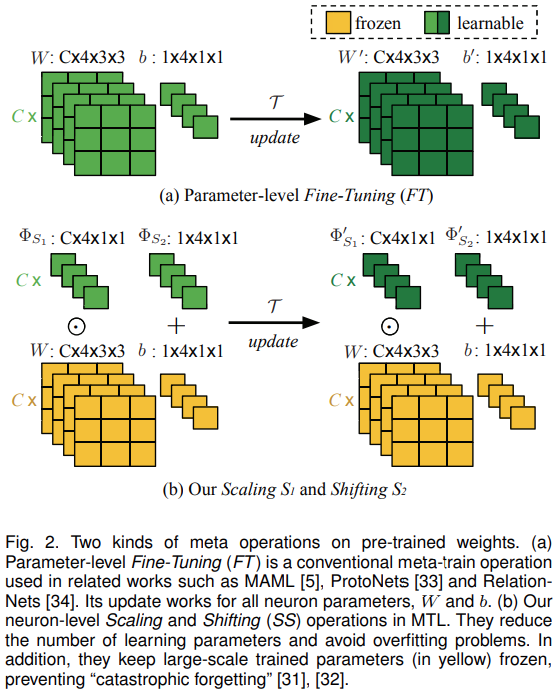
SS相对于“遗忘”问题有明显优势,避免以往学习的经验丢失;由大规模训练的DNN初始化,可以快速拟合;参数量少。
通过SS和FT(精细调整)进行更新的区别如下图:
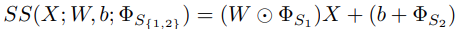
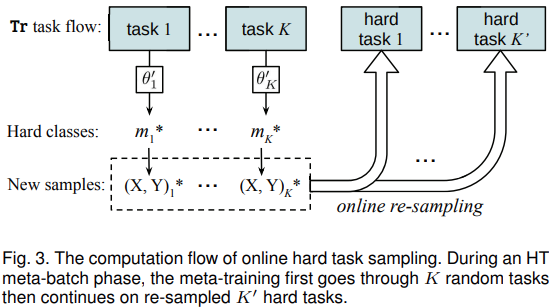
Hard task (HT) meta-batch
对于元任务集合$\tau$,在每次更新后,选择最低的精度排序来确定当前系统中最困难的分类样本进行任务的重新采样
Meta-gradient regularization
- 使元学习器减少对先前情节的遗忘
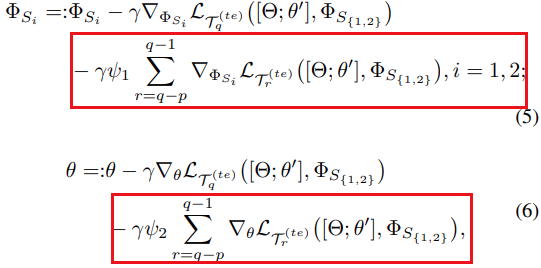
整体算法

实验
数据集:miniImageNet,tieredImageNet, Fewshot-CIFAR100(FC100)
基线对比
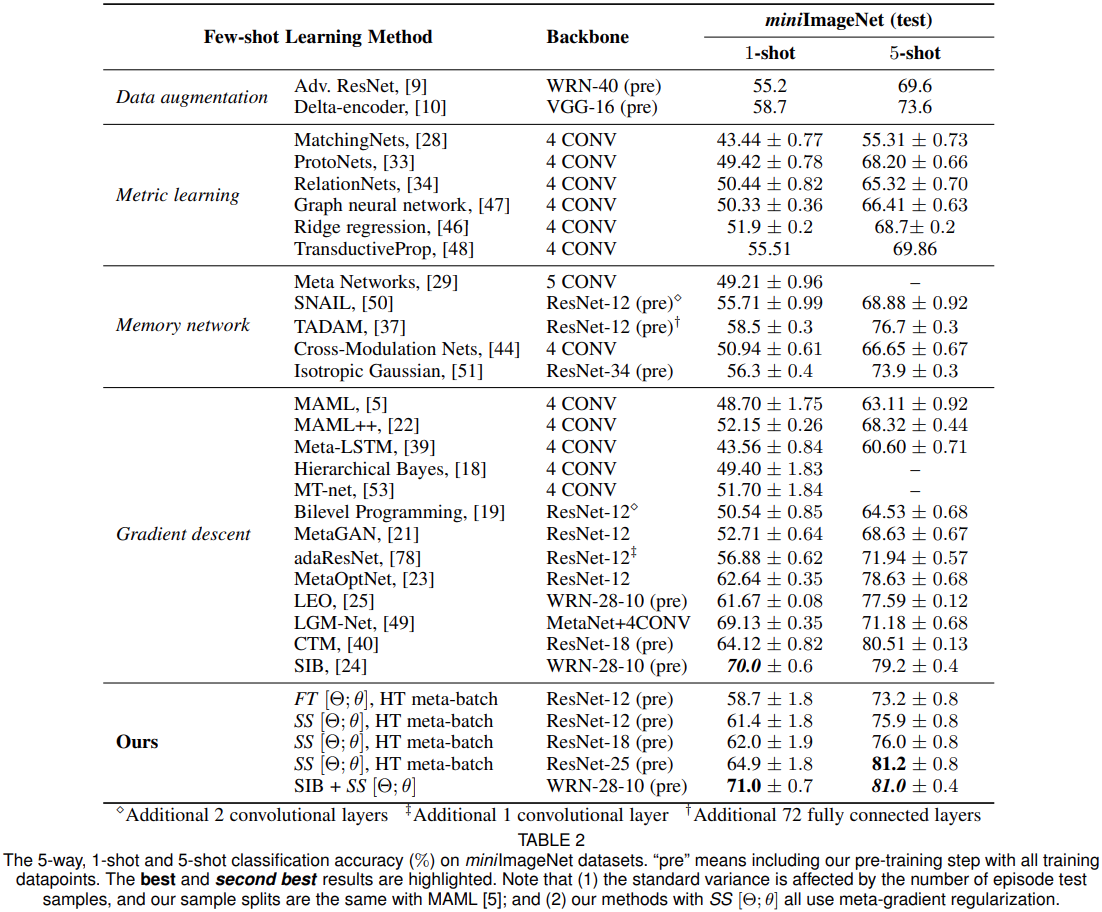
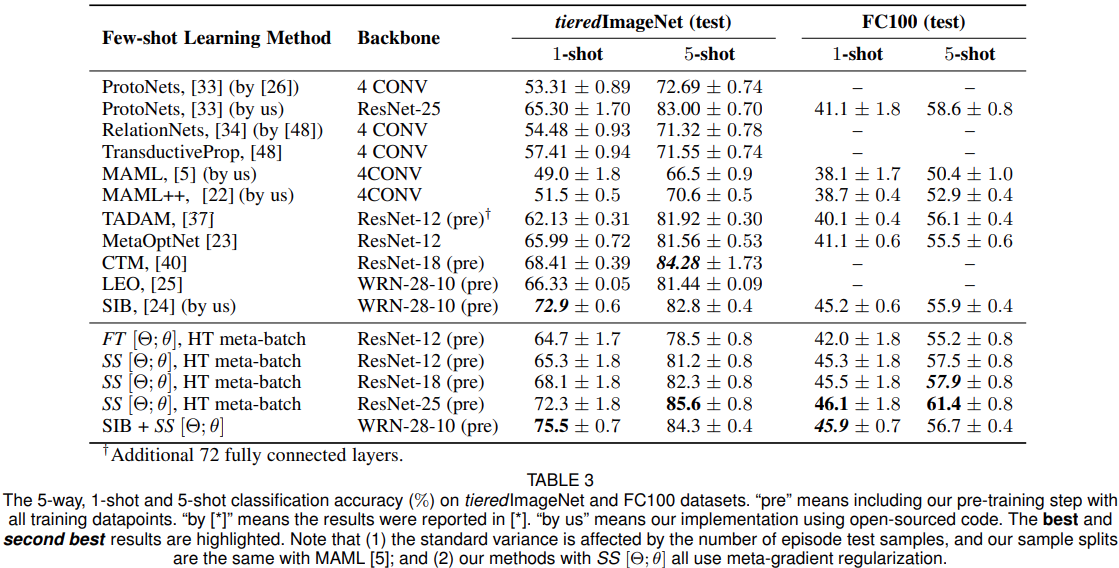
组件验证(SS与FT对比)
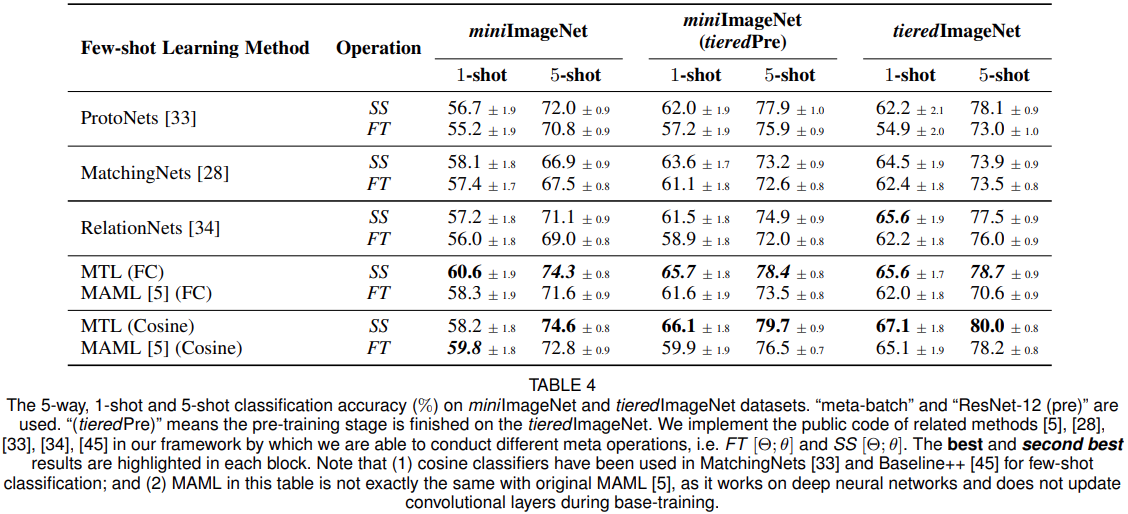
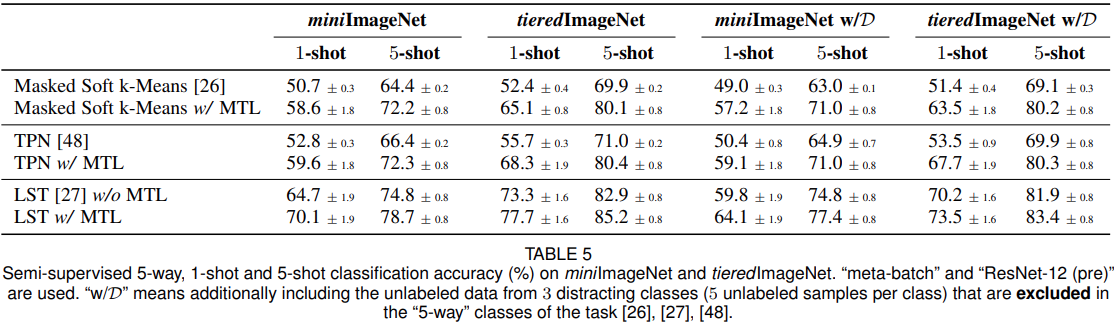
消融实验
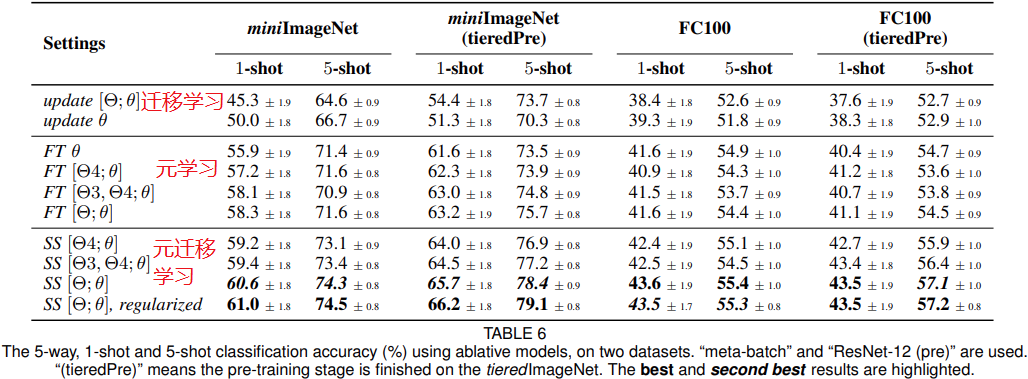
MTL vs. No meta-learning. 表6在最上面的块中显示了无元学习方法的结果。本文提出的方法取得了明显更好的性能。
SS[Θ;θ]works better than light-weight FT variants. 表6显示使用SS[Θ;θ]的方法在所有设置中均达到了最佳性能,且SS始终优于FT。
Meta-gradient regularization is effective. 表6最后两行显示了有效性。正则化迫使元学习器减少对先前情节的遗忘,并稳定元梯度。
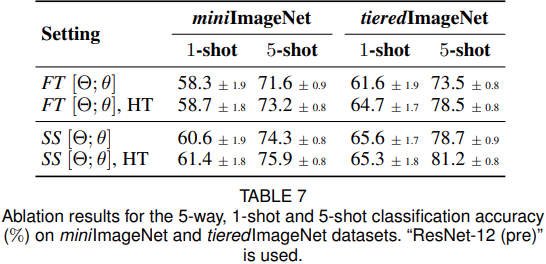
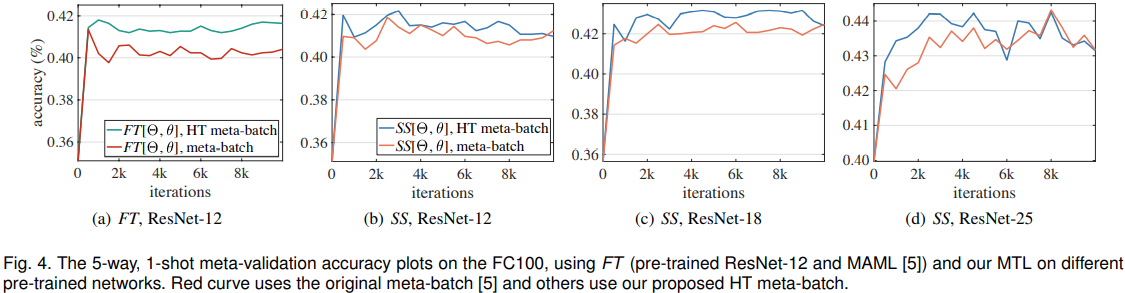
Accuracy gain by HT meta-batch. 表7、图4显示:HT meta batch可以提高模型的准确率。
Speed of convergence of MTL with HT meta-batch. (a)~(d)中HT mete-batch仅需1~4k次迭代达到很好的性能,而没有进行深度预训练网络的MAML需要200k次迭代。
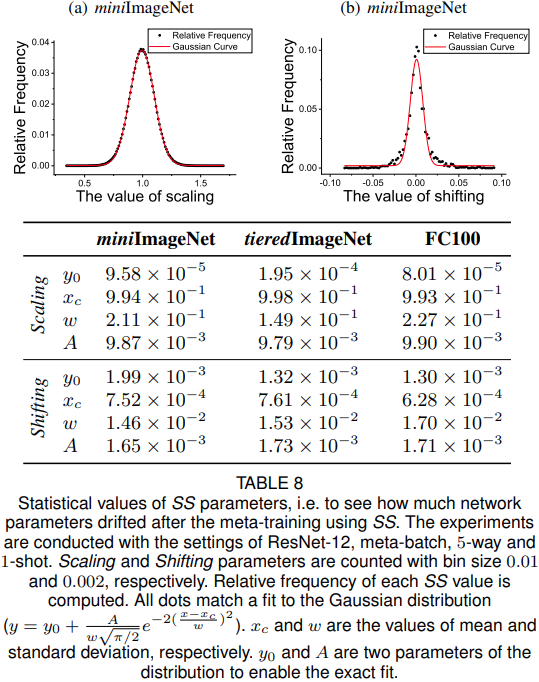
SS统计分析
表8中提供了有关学习到的SS权重的统计信息。 (a)和(b)中的每个点表示这些数字的分布,与高斯分布(红色)很好地匹配。
结论
事实证明,MTL在预训练的DNN神经元上的关键操作对于使学习经验适应未知任务非常有效。
MTL的持续改进证明了大规模预训练有素的深度网络可以提供良好的“知识基础”,以进行有效的一次性学习。
就学习方案而言,HT meta-batch对于消融模型始终表现出良好的性能,而且对提高收敛速度特别有用。
展望:本文模型独立于任何特定的模型或体系结构,并且只要在在线迭代中易于评估任务的难度即可很好地推广。