关键词:时间序列预测;
1摘要
Informer的主要工作是使用Transfomer实现长序列预测(Long Sequence Time-Series Forecasting),以下称为LSTF。针对Transfomer在长序列预测中的不足(平方时间复杂度、高内存占用和现有编解码结构的局限性),提出ProbSparse注意力机制、自注意力蒸馏技术和生成式解码器等模块解决或缓解上述问题。
- 首先,LSTF任务具有重要研究意义,对政策计划和投资避险等多种需要长时预测的任务至关重要;
- 目前现有方法多专注于短期预测,模型缺乏长期预测能力;
- Transformer具有较强捕获长距离依赖的能力,但是,在计算时间复杂度和空间复杂度以及如何加强长序列输入和输出关联上都需要优化;
本文提出的方案同时解决了上面的三个问题,我们研究了在self-attention机制中的稀疏性问题,本文的贡献有如下几点:
- 我们提出Informer来成功地提高LSTF问题的预测能力,这验证了类Transformer模型的潜在价值,以捕捉长序列时间序列输出和输入之间的单个的长期依赖性;
- 我们提出了ProbSparse self-attention机制来高效的替换常规的self-attention并且获得了O(LlogL)的时间复杂度以及O(LlogL)的内存使用率;
- 我们提出了self-attention distilling操作,它大幅降低了所需的总空间复杂度;
- 我们提出了生成式的Decoder来获取长序列的输出,这只需要一步,避免了在inference阶段的累计误差传播;
输入: 时间 t
输出: 时间 t, 且
2. 编解码结构
编解码结构通常这样设计:将输入编码为隐层状态
,然后将隐层状态解码为输出表示
。通常推理阶段采用step-by-step方式,即动态解码。具体为:输入上一步隐层状态
和上一步的输出计算k+1步的隐层状态
,然后预测第k+1步的输出
。
3. 输入表示
方法介绍

在LSTF问题中,时序建模不仅需要局部时序信息还需要层次时序信息,如星期、月和年等,以及突发事件或某些节假日等。经典自注意力机制很难直接适配,可能会带来query和key的错误匹配问题,影响预测性能表现。

左边:编码过程,编码器接收长序列输入(绿色部分),通过ProbSparse自注意力模块和自注意力蒸馏模块,得到特征表示。(堆叠结构增加模型鲁棒性)
右边:解码过程,解码器接收长序列输入(预测目标部分设置为0),通过多头注意力与编码特征进行交互,最后直接预测输出目标部分(橙黄色部分)。

Informer编码器的架构。 (1)每个水平堆栈代表图(2)中的单个编码器副本; (2)较高的堆栈是主堆栈,它接收整个输入序列,而第二个堆栈则占输入的一半。 (3)红色层是自注意机制的点积矩阵,通过在每层上进行自注意蒸馏而逐渐减少级联; (4)将2堆栈的功能图连接为编码器的输出。
4.设计的关键
作者的insight是,如果将self-attention中的点积结果进行可视化分析,会发现服从长尾分布,
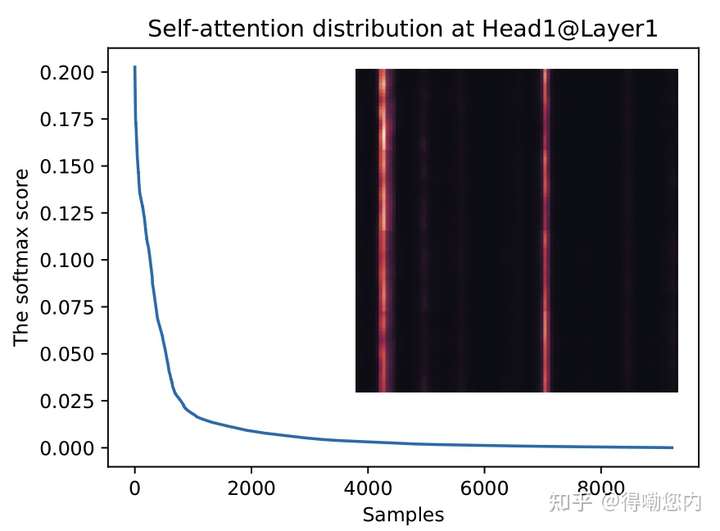
也就是少数的几个query和key的点积计算结果主导了softmax后的分布,这种稀疏性分布是有现实含义的:序列中的某个元素一般只会和少数几个元素具有较高的相似性/关联性。
经过简化后,作者定义第i个Query的稀疏性度量公式为:
第一项是在qi所有keys的Log-Sum-Exp(LSE),第二项是arithmetic均值
如果第i个query的M值较大,说明它的注意力概率p相较其他部分差异性较大,比较大可能性是重要性部分。
基于上述度量方法,ProbSparse自注意力计算方式可以表示为:,其中
为稀疏矩阵包含TOP u个query。通过该优化,没对query-key计算需要
计算复杂度。计算M的计算复杂度为
的二次方。所以,作者采用近似思想进行了进一步的优化与化简。
Self-attention Distilling
self-attention蒸馏的insight是随着Encoder层数的加深,由于序列中每个位置的输出已经包含了序列中其他元素的信息(self-attention的本职工作),我们可以缩短输入序列的长度。”蒸馏”操作主要为使用1D卷积和最大池化,将上一层的输出送至魔改后的多头注意力模块之前做维度修剪和降低内存占用。
所以Encoder类似于金字塔结构:
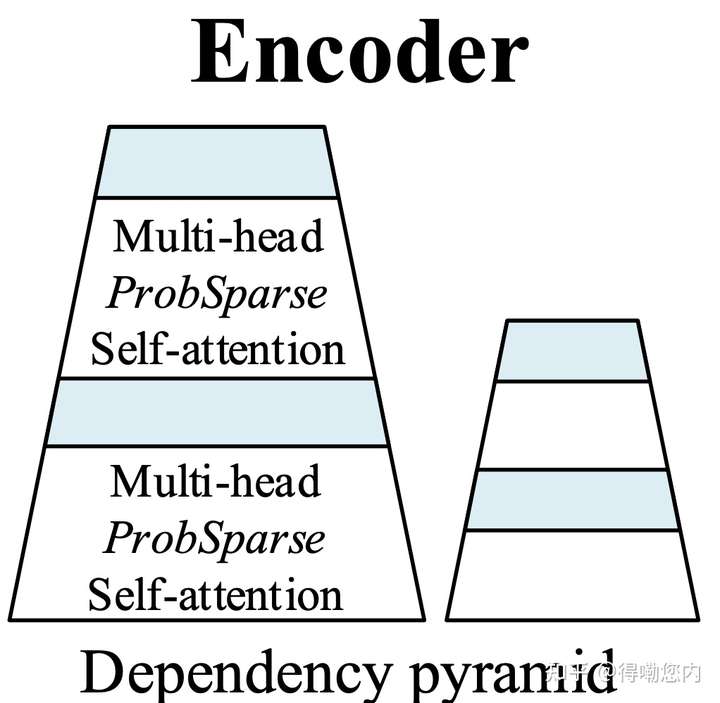
如何缩短序列长度呢?卷积+最大池化。
基本上每一层序列长度会减半。
decoder上:一次前向计算,预测长序列输出。采用标准解码器结构,即堆叠两个相同的多头注意力层。不同的是,本文采用的是生成式预测(不是step-by-step方式)直接输出多步预测结果。
5.结果

本文研究了长序列时间序列预测问题,提出了长序列预测的Informer方法。具体地:
- 设计了ProbSparse self-attention和提取操作来处理vanilla Transformer中二次时间复杂度和二次内存使用的挑战。
- generative decoder缓解了传统编解码结构的局限性。
- 通过对真实数据的实验,验证了Informer对提高预测能力的有效性
有知乎答主 表示Informer的主要目的就是效率优化:对self-attention的时间空间优化、卷积池化蒸馏