Introduction
关键词:时间序列;时序分类
Abstract
随着可用时间序列数据的增加,预测它们的类别标签已成为广泛学科中最重要的挑战之一。最近关于时间序列分类的研究表明,卷积神经网络(CNN)作为单一分类器实现了最先进的性能。本文指出现有CNN分类器通常采用的全局池化层丢弃了高层特征的时间信息,因此提出了一种动态时间池(DTP)技术,通过分段聚合特征,减少了隐层表示的时间长度。为了将整个序列划分为多个片段,本文使用动态时间规整(DTW)将每个时间点按照时间顺序与片段的原型特征对齐,这可以同时与CNN分类器的网络参数进行优化。结合DTP层和全连接层,有助于进一步提取区分性特征。在单变量和多变量时间序列数据集上的大量实验表明,本文提出的池化方法显著提高了分类性能。
Motivation
- CNN等方法不能有效利用高级特征的时序信息,CNN分类器往往采用全局平均池化(GAP)或全局最大池化(GMP),简单地沿时间轴聚合所有隐藏向量。这样的全局聚合丢弃了隐藏特征的时间位置,使得CNN只学习到位置不变的时间特征
Contribution
- 提出了一种新的池化方法,可以有效地减少网络输出的时间大小(即长度),同时最小化时间信息的损失。
由于观察到时间序列实例由多个具有不同模式的片段组成,动态时间池(DTP)为每个片段输出一个池向量,而不是为整个序列输出一个。DTP层通过在每个段中聚合隐藏向量来产生段级表示,因此它能够基于段特定的类权重来建模分类得分。换句话说,CNN分类器用segment-level池代替了全局池(后面跟着一个完全连接的层),这允许进一步提取类区别特征,提高分类精度。本文还专门为DTP层提供了类激活图(CAM),指出每个时间区域对预测输入时间序列的类标签有多少贡献。
- 挑战:从输入时间序列实例中找出一致的片段,这些片段在时间上没有相互对齐。
- DTP层使用动态时间规整(DTW)进行语义分割。
- 首先引入可训练的潜在向量,其数量与待识别的片段数相当,称为原型隐藏序列,用于按时间顺序将每个片段的原型特征编码成它们。
- 再者,DTP层将网络输出(即隐藏向量序列)与原型隐藏序列进行对齐,同时基于DTW保持其时间顺序;这将生成与每个片段匹配的连续时间点集。同时优化CNN和原型隐藏序列,也就是说,训练CNN有助于捕捉片段的原型特征,学习原型隐藏序列有助于CNN提取判别特征。
Related Work
Deep Learning for Time Series Classification
时间池化
多个卷积层的堆栈输出每个时间点的隐藏向量,该隐藏向量最终编码了上下文的高级特征。基于global average pooling (GAP)或global max pooling (GMP),将所有隐藏向量沿着时间轴汇总成一个向量(图1a),最后用它来计算分类得分。
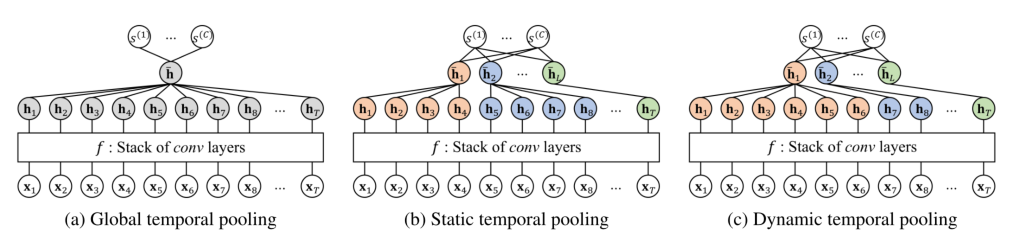
然而,这样的全局池化会丢失高级特性的时间动态信息,从而导致性能有限。在时间序列分类的情况下,局部时间模式可以有不同的含义,取决于它们的时间发生位置
Differentiable Dynamic Time Warping
DTW是一种基于时间一致性的点对点匹配来测量两个不同长度时间序列之间距离的流行技术。给定两个长度为M和N的序列X和Y,其代价矩阵$\Delta(X, Y) \in\mathbb{R}^{M \times N}$的(m, n)便是$X_m、Y_n$之间的距离(或对齐代价)。X与Y之间的DTW距离由代价矩阵与任意二值对齐矩阵A的最小内积定义
$\mathcal{A} \in \mathbb{R}^{M \times N}$表示是否对齐
Dynamic Temporal Pooling
Problem Formulation
N个时间序列样本和标签
时间序列样本(D个变量,长度为T)
CNN输出隐层时序向量
分类分数
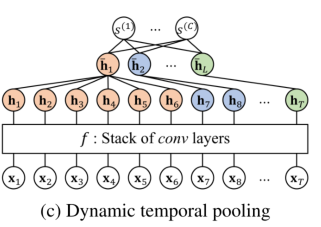
Temporal Pooling based on Segmentation
- 时间池化的目的是减少隐藏表示(即f的输出)的时间大小T,同时最小化时间序列中时间信息的丢失。
- 关键思想是将一系列隐藏向量分割成L段,然后通过汇总每个段中的向量生成池表示。正式地说,时间池化层输出序列池化向量$\overline{\mathbf{H}}=\left[\overrightarrow{\mathbf{h}}{1}, \ldots, \overline{\mathbf{h}}{L}\right] \in \mathbb{R}^{K \times L}$, 长为L。第l个向量形式化如下:
$\phi$是池化操作,$\mathcal{T}{l}=\left{t{l-1}+1, \ldots, t_{l}\right}$为属于第l段的连续时间点集合,池化操作可以使用三个函数:计算平均值(用avg表示)、求和值(用sum表示)和最大值(用max表示)。
分割
分割的一个简单策略是以静态方式将整个时间序列分割成相同长度的短序列,但它也存在一些需要解决的局限性:
- (模式不对齐)不同样本的时间序列,不是时间对齐的,这使得它很难找到绝对的时间位置分割(下图,upper)
- (模式时间长度不同)此外,考虑分段任务的目的是发现内在同质的不同时间模式,在大多数情况下,每个最优时间序列分段的长度不可能与其他的相同(下图,lower)
DTW
通过将每个时间点与它在时间顺序上语义上最近的片段匹配来执行语义分割。
引入原型隐层序列
长度为L的片段,最好地总结了L片段的高级特征
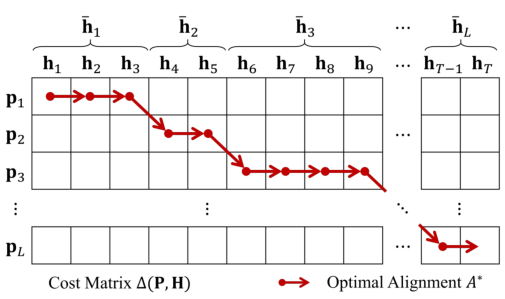
DTW匹配
利用DTW将原型隐藏向量序列(即$\mathbf{P}$)与目标隐藏向量序列(即$\mathbf{H}$)进行时间对齐。根据DTW比对的结果,将隐藏向量序列分成L段,每一段由式进行合并。在这种情况下,$\mathbf{P}$和$\mathbf{H}$之间的最优对准矩阵$A^{*}$可由
$\Delta \in \mathbb{R}^{L \times T}$是对齐成本矩阵,$\delta\left(\mathbf{p}{l}, \mathbf{h}{t}\right)=1-\frac{\mathbf{p}{l} \cdot \mathbf{h}{t}}{\left|\mathbf{p}{l}\right|{2}\left|\mathbf{h}{t}\right|{2}}$表示为$\mathbf{p}{l} \text { and } \mathbf{h}{t}$的距离
与原始的DTW不同,为了限制每一个时间点只能匹配一个段,只能向右或者向右下角移动
Learnable Dynamic Temporal Pooling Layer

Experiments
Experimental Settings
Datasets
- 85个单变量时间序列数据集(UCR)
- 30个多变量时间序列数据集(UEA)
Baseline
分别使用avg、sum和max操作:全局时间池(GTP)、固定池大小的静态时间池(STP)和动态时间池(DTP)。
Evaluation
为了进行定量评估,进行了两两的posthoc analysis,根据多个数据集的准确性,统计上对不同分类器进行排名。通过临界差值(CD)图将结果可视化,该图用粗水平线表示每个分类器的平均级别。对于所有的数据集,用不同的随机种子重复训练每个分类器三次,并报告中位数精度。
Comparison of Different Pooling Layers
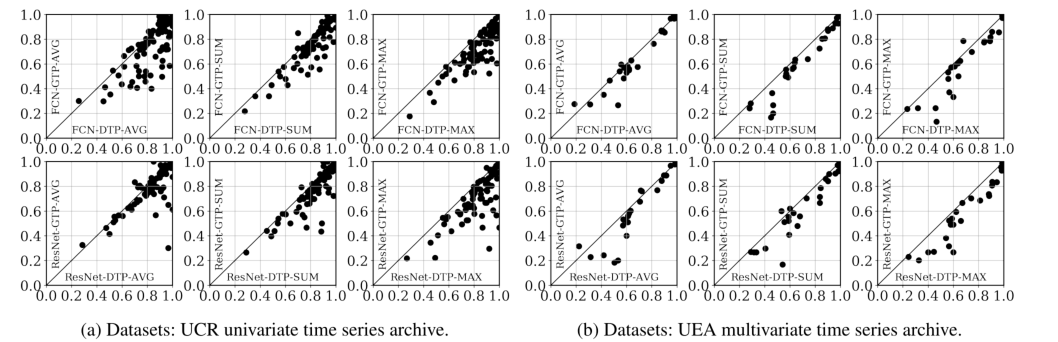
首先直接比较本文提出的CNN分类器(使用DTP)和基线CNN分类器(使用GTP)的分类精度。单个点表示每个数据集,因此每个点距离y = x线的距离表示两种池化方法之间的性能差距。
- 在所有的情况下,我们观察到大部分的数据集都点在每个图的右下角,这表明不管DTP的CNN架构和池操作如何,DTP的性能都优于GTP。特别是,当DTP与max操作一起使用时,它比GTP的性能改进更大。
- 由于最大池化可以有效地检测到一般的特定特征,DTP-MAX擅长于细分发现这些特征,这使得最终的表示进一步具有类区别性。
为了进行更多的统计评估,本文还基于两两统计检验比较了不同的时间池化方法(即GTP、STP和DTP)下图显示了它们在一组数据集上的平均rank,具有两两统计差异。粗横线显示一组分类器无显著差异(p = 0.05)。
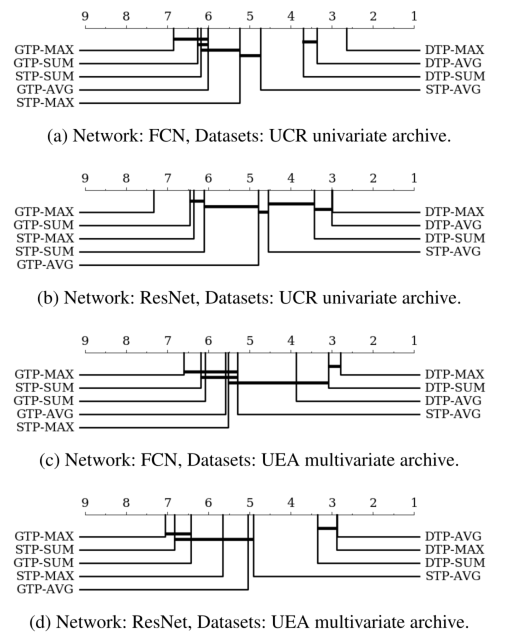
- DTP在所有类型的时间池中始终表现最好
- GTP表现最差。
- 在STP的情况下,尽管与DTP考虑的段数相同,它的性能略好于GTP,但在统计上没有太大的差异;这意味着在固定的时间位置汇集来自相同长度段的向量不能有效提高CNN分类器的精度。相反,本文的DTP方法,使用变长段被大田、能够建模的高级特性取决于每一段,因此其判别能力提高了很多。可以得出结论,DTP成功地利用时间信息进行分类
Parameter Analysis on L
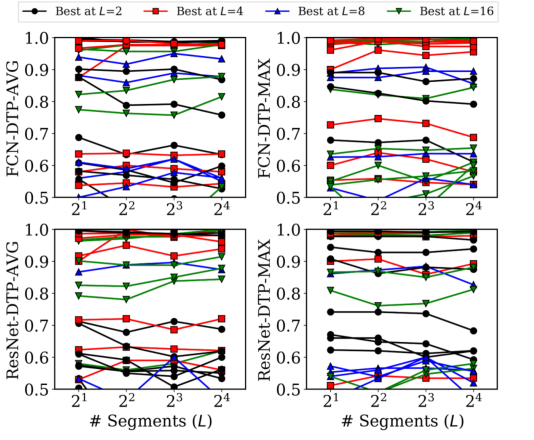
单线表示每个数据集,其颜色由精度最高的L的最优值决定。
- 性能的变化曲线在大多数数据集上是不一致的,而且最优的分段数也会随着数据集的不同而变化
- 为目标数据集找到最优的L值可以在实践中进一步提高CNN分类器的性能
Qualitative Analysis
Class Activation Map(类激活图)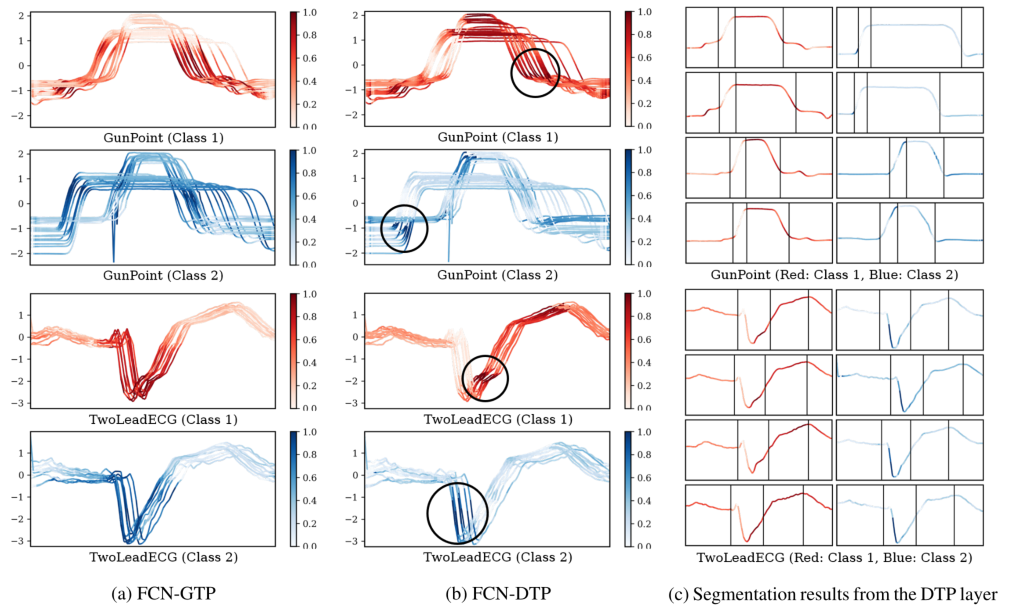
- 为了定性地比较GTP和DTP的定位性能,本文通过突出显示按分数成比例的输入时间序列来可视化他们的CAM分数。在上图a和b中,class 1和class 2的时间序列实例分别用红色和蓝色表示,对于每个时间序列实例,本文使用在[0,1]范围内归一化后的CAM分数。尽管这两个CNN分类器对这两个数据集(即GunPoint和TwoLeadECG)实现了几乎相同的精度,但它们突出了不同的区域,作为最有助于预测其类标签的判判性时间模式。值得注意的是,与GTP相比,DTP发现的局部区域在类之间的可区分性更强,这使得CNN分类器具有更好的可解释性。
- 上图c给出了DTP层的分割结果;每个时间序列实例通过垂直线分为四个部分。第l段(l = 1,…,4)所有实例共享相似(或一致的)时间模式,即使它们的原始输入序列不是时间对齐的。结果表明,原型隐序列P成功地按时间顺序编码了片段的原型高级特征,因此DTP层可以基于P和H之间的DTW对齐进行语义分割。