时间序列异常点的无监督检测是一个具有挑战性的问题,它需要模型推导出一个可识别的准则。以往的方法主要是通过学习点表示或成对关联来解决这一问题,但这两种方法都不足以对于复杂情况进行检测。近年来,Transformers在点态表示和成对关联的统一建模中表现出了巨大的威力,我们发现每个时间点的自我注意权重分布可以体现出与整个序列的丰富关联。我们的主要观察结果是,由于异常的罕见性,从异常点到整个序列建立非平凡的关联非常困难,因此,异常的关联应主要集中在其相邻的时间点上。这种相邻的关联性偏差意味着一种基于关联的标准,可以在正常点和异常点之间进行固有的区分,我们通过关联差异来强调这一点。在技术上,我们提出了一种新的异常注意机制来计算关联差异的 Anomaly Transformer。设计了一种极大极小策略来增强关联差异的正常-异常区分能力。
1、INTRODUCTION
现实世界中的系统总是以连续的方式工作,它可以生成由多个传感器监测的多个连续测量,如工业设备、空间探测器等。从大规模系统监测数据中发现故障可以简化为从时间序列中检测异常时间点,这对于确保安全和避免经济损失是非常有意义的。但异常通常很罕见,并且被大量的正常点隐藏,这使得数据标记困难且昂贵。因此,我们将重点放在无监督的时间序列异常检测上。
无监督时间序列异常检测在实践中极具挑战性。模型应该通过无监督任务从复杂的时间动态中学习信息表示。不过,它也应该有能力推导出一个可区分的标准,可以从大量正常时间序列中检测罕见的异常。各种经典异常检测方法提供了许多无监督的范例,但是经典异常检测方法(例如LOF、OC-SVM)很少考虑时间信息,这使得他们在时序场景中应用受限。
因此研究人员开始将目光投向深度学习领域,往往是通过循环网络(RNN)学习时序数据点级别的表征,进而依靠重建或预测误差(自回归)进行判定,这里,一个自然而实用的异常检测标准是逐点重建或预测误差。然而,由于异常的罕见性,对于复杂的时间模式,逐点表示的信息较少,并且可以由正常的时间序列数据主导,使得异常不易区分。此外,重建或预测误差是逐点计算的,这无法提供对时间上下文信息的全面描述。
另一类主要的方法是基于显式关联建模来检测异常。向量自回归和状态空间模型属于这一类。通过将不同时间点的时间序列表示为顶点,并通过随机游走检测异常,该图也被用于明确捕捉关联(Cheng等人,2008;2009)。一般来说,这些经典方法很难学习信息表示和对细粒度关联建模。最近,图形神经网络(GNN)已被应用于学习多元时间序列中多变量之间的动态图,虽然学习到的图更具表现力,但仍然局限于单个时间点,这对于复杂的时间模式来说是不够的。此外,基于子序列的方法通过计算子序列之间的相似性来检测异常(Boniol&Palpanas,2020)。在探索更广泛的时间背景时,这些方法无法捕捉每个时间点和整个序列之间的细粒度时间关联
因此,如何获取更具信息含量的表征,进而定义更加具有区分性的判据对于时序异常检测尤为关键。
transformer的成功归功于对序列长程全局依赖的建模学习(global representation and long-range relation),我们发现每个时间点的时间关联(association)都可以从自我注意图中获得,该图表现为其关联权重在时间维度上对所有时间点的分布。每个时间点的关联分布可以为时间上下文提供更详细的描述,指示动态模式,例如时间序列的周期或趋势。我们将上述关联分布命名为序列关联(series-association),可通过transformer从原始序列中发现
同时,相比于正常点来说,异常点很难与序列的所有点都构建很强的关联,且由于连续性往往更加关注邻近区域。异常关联应集中在相邻时间点, 这些时间点更有可能包含类似的异常模式。这种相邻的关联性偏差称为先验关联(prior-association)。 相比之下,主要的正常时间点可以发现与整个序列的信息关联,而不限于相邻区域。基于这一观察,我们试图利用关联分布的正常异常区分能力。这为每个时间点带来了一个新的异常标准,该标准通过每个时间点的先验关联与其序列关联之间的距离来量化,称为关联差异。如上所述,由于异常的关联更可能是相邻的,因此异常将呈现比正常时间点更小的关联差异。
基于上述观察,我们提出了Anomaly Transformer模型用于建模时序关联,为了计算关联差异,我们将自我注意机制改进为异常注意,它包含两个分支结构,分别对每个时间点的先验关联和序列关联进行建模。先验关联使用可学习的高斯核表示每个时间点的邻接关联偏差,而序列关联对应于从原始序列中学习的自我注意权重。 同时利用极小极大(Minimax)关联学习策略进一步突出正常、异常点之间差别,实现了基于关联差异(Association Discrepancy)的时序异常检测。Anomaly Transformer在不同领域的5个数据集上都取得了SOTA的效果。
2、方法:
作者强调无监督时间序列异常检测的关键是学习信息表示和找到可区分的标准。我们提出了Anomaly Transformer 来发现更多信息关联,并通过学习关联差异来解决这个问题,
Anomaly transformer模型包含用于建模时序关联的Anomaly-Attention,其整体结构是Anomaly-Attention和前馈层的交替堆叠,这有利于模型从多层次深度特征中学习潜在的时序关联。
如下图所示,Anomaly-Attention(左)同时建模了数据的先验关联(Prior-Association,即更关注邻近区域的先验)和序列关联(Series-Association,即从数据中挖掘的依赖)。除了重建误差之外,我们的模型还采用了极小极大策略(Minimax)用于进一步增大异常点和正常点所具有的关联差异的差距。该策略带有一个特殊设计的停止梯度机制(灰色箭头),以约束先验关联和序列关联,从而获得更明显的关联差异。

2.1 Anomaly-Attention的具体设计
我们提出的一种新的注意力机制Anomaly-Attention,用于统一建模先验关联和序列关联,进而方便关联差异的计算。
对于先验关联
,我们采用了可学习的高斯核函数,其中心在对应时间点的索引上。这种设计可以利用高斯分布的单峰特点,使数据更加关注邻近的点。同时,为了使得先验关联能够适应不同的时序模式,高斯核函数包含可学习的尺度参数
。
对于序列关联
,它是由标准Transformer中注意力计算获得,一个点的序列关联即是该点在注意力矩阵中对应行的注意力权重分布。该分支是为了挖掘原始序列中的关联,让模型自适应地捕捉最有效果的关联。
与逐点表征相比,我们的两种关联都很好地表示了每个点在时间维度上的依赖,这使得表征具有了更丰富的信息。它们也分别反映了邻近先验和习得的真实关联。这两者之间的差异,即为关联差异(Association Discrepancy),可以天然地将正常点和异常点区分开来。

2.1.1 关联差异(Association Discrepancy)
通过上面的网络结构获得了Prior-association 和Series-association
后,可以定义Association discrpancy
上式利用了symmetrized KL散度计算每层中得到的两个分布的差异,这代表了这两个分布之间的信息增益,每个时间点对应一个值,异常数据相比正常数据AssDis的值会较小。
2.2 极大极小策略

为了无监督地学习表征,我们利用重建误差来进行模型优化。同时,为了加大正常点和异常点之间的差距,我们使用了一个额外关联差异损失来增大关联差异。在这种设计下,由于先验关联的单峰特性,新增的关联差异损失会驱使序列关联更加关注非邻近的区域,从而使得异常点的重建更加的艰难,进而更加可辨别。
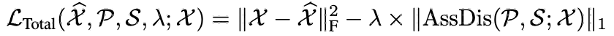
然而直接最小化关联差异将使得高斯核的尺度参数急剧变小,结果就会导致先验分布无意义。因此,为了更好的控制关联学习的过程,我们采用了一种Minimax策略。在最小化阶段,先验关联将高斯核导出的分布族中的关联差异最小化。在最大化阶段,序列关联使重构损失下的关联差异最大化。
在最小化阶段,我们让先验关联近似从原始时序中学得的序列关联
,该过程将使得先验关联适应不同的时序模式。在最大化阶段,我们优化序列关联
来最大化关联之间的差异,该过程将使得序列关联更加注意非临接的点,使得异常点的重建更加困难。
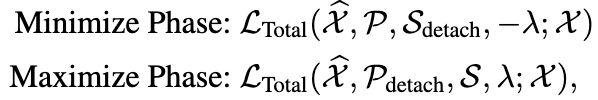
最终,我们将标准化后的关联差异与重建误差结合起来制定了新的异常检测判据:
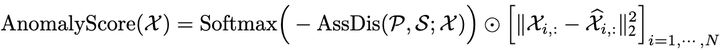
实验结果与可视化分析

消融实验:


总结:
本文研究无监督时间序列异常检测问题。与以前的方法不同,我们通过transformer学习了更多信息的时间点关联。在关联差异关键观测的基础上,提出了一种异常变压器(Anomaly Transformer),该变压器包含一个具有双分支结构的异常注意来体现关联差异。采用极大极小策略进一步放大正常和异常时间点之间的差异。通过引入关联差异,提出了基于关联的准则,提高了重构性能