摘要
时间序列预测在日常生活中有着广泛的应用,并且是一个有挑战的任务,因为时间序列的性质会随时间变化,这被称为分布偏移(distribution shift)。
本文提出了时间序列的时序协方差漂移问题(Temporal Covariate Shift, TCS),进而提出了AdaRNN方法解决了此问题。AdaRNN主要由两个部件组成,第一个组件用于刻画时间序列中的分布信息,第二个组件用于减少分布的错误匹配并学习一种基于rnn的自适应时间序列预测模型。AdaRNN是一个集成了多种灵活分布距离的通用框架。
在分类和回归问题上比对比方法提高2.6%和9.0%的精度(RMSE)。另外,AdaRNN可以被简单地扩展到Transformer框架下,同样能够提高其表现。
资源链接
论文地址:https://arxiv.org/abs/2108.04443
代码链接:https://github.com/jindongwang/transferlearning/tree/master/code/deep/adarnn
知乎讲解:https://zhuanlan.zhihu.com/p/398036372
视频讲解:https://www.bilibili.com/video/BV1Gh411B7rj/
引言
背景
时间序列 (Time Series)在日常生活中有着广泛的应用,例如,天气预测、健康数据分析,以及交通情况预测等实际问题均需要对时间序列进行建模。所谓时间序列,指的是按照时间、空间或其他定义好的顺序形成的一条序列数据。由于时间的连续性,不难想像,时间序列数据会随着时间动态变化。特别地,时间序列的一些统计信息 (例如均值、方差等)会随着时间动态变化。统计学通常将此类时间序列称为非平稳时间序列 (Non-stationary Time Series)。为解决此问题,传统方法通常基于马尔可夫假设来进行建模,即时间序列上的每个观测仅依赖于它的前一时刻的观测。依据此假设,隐马尔可夫模型、动态贝叶斯网络、卡尔曼滤波法以及其他统计模型如自回归移动平均模型 (Autoregressive Integrated Moving Average Model, ARIMA)发挥了重要作用。最近几年随着深度学习的兴起,基于循环神经网络 (Recurrent Neural Networks, RNNs)的方法取得了比之前这些方法更好的效果。与其相比,循环神经网络对时间序列的时间规律不做显式的假设,依靠强大的神经网络,RNN能自动发现并建模序列中高阶非线性的关系,并且能实现长时间的预测。因此,RNN系列方法在解决时间序列建模上十分有效。
时序协方差漂移问题(TCS)
==即:在前一段分布学习到的模式迁移到新一种分布上效果变差==
Temporal Covariate Shift,也可以叫时序协变量漂移(偏移),认为时间序列可以依据分布被切分成多个不同的段,并且在进行时间序列预测时前面的分布可见,但后面的分布不可见。
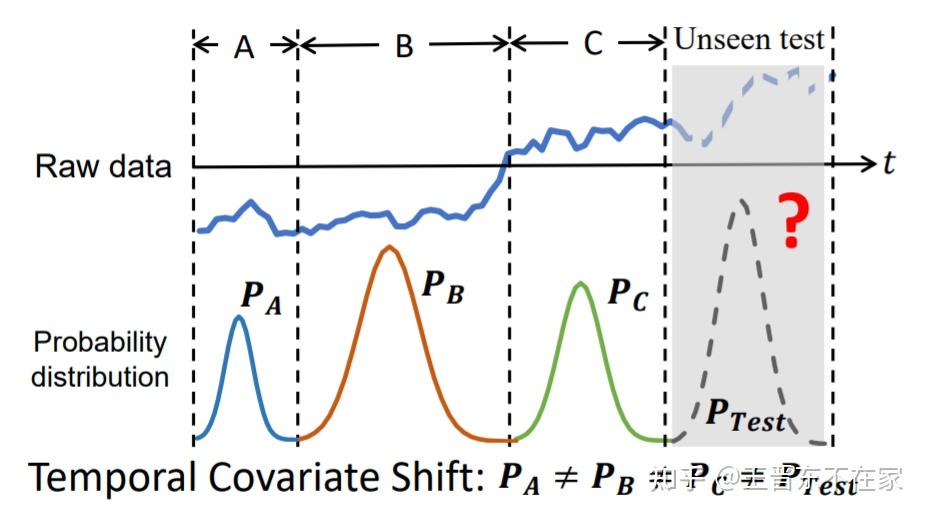
时序协方差定义和协方差漂移(Covariate Shift)类似,边缘概率分布不同,条件概率分布相同
协方差漂移是train和test区别,这里是每一段时间序列(上图A、B、C等)之间的区别

RNN在面对未知的数据分布时,其很可能会发生模型漂移 (Model shift)现象(出现未见过的分布)
- 时间序列的数据分布具有连续性。由于其每个时刻的数据分布都在改变,因此我们需要找到一种方法将连续的分布差异变成离散的、可计算的分布差异,最大限度地利用这些不同分布中的公共知识
- 开发一个基于RNN的分布匹配算法在捕获时间依赖性的同时,最大限度地减少它们的分布发散
贡献
1) 提出新问题:时序协方差漂移
2) 提出通用框架:AdaRNN来解决该问题(提出划分不同分布的方法,以及利用RNN的隐层更细粒度地缩小域间差异)
3) 有效性:SOTA于分类和多个回归任务
相关工作
时间序列相关:
CNN,RNN,LSTM等
分布匹配(迁移学习相关):
写者注:我觉得不用太纠结下面这段,这篇文章的思想还是偏DG的,下面似乎是在说CV的迁移学习
本文的研究与域自适应(DA)和域泛化(DG)有区别,因为:
DA和DG并不用于时间分布的表征,因为域在它们的问题中是预先给定的
DA和DG在分类任务上通常用CNN而不是RNN,
方法
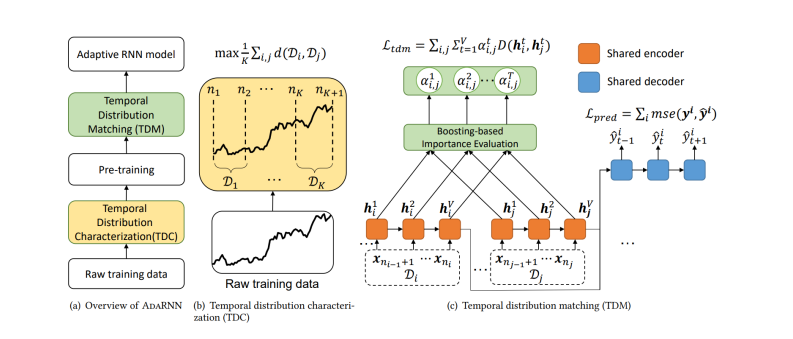
总述
分为两步:
时序相似性量化 (Temporal Distribution Characterization, TDC)(黄色)
将时间序列中连续的数据分布情形进行量化,以将其分为 段分布最不相似的序列。其假设是如果模型能够将此
段最不相似的序列的分布差异减小,则模型将具有最强的泛化能力。因此对于未知的数据预测效果会更好。
时序分布匹配 (Temporal Distribution Matching, TDM)(绿色)
为上述 段时间序列构建迁移学习模型以学习一个具有时序不变性的模型。
时序相似性量化TDC
为将时间序列切分为 段最不相似的序列(对应于正式中的求最大值操作、同时使得
最小),时序相似性量化方法将此问题表征为一优化问题:
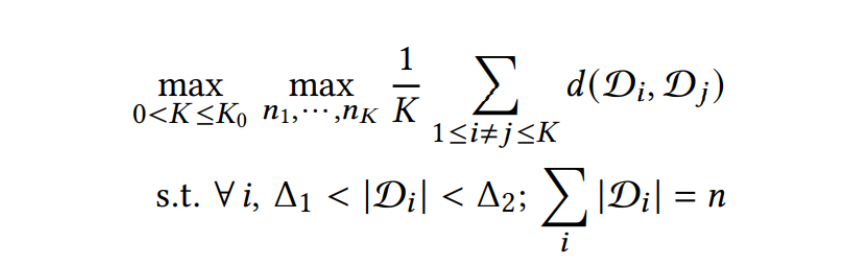
其中 是相似度度量函数,
和
是为了避免无意义的解而预先定义好的参数。上述优化问题可以用动态规划算法 (Dynamic Programming)进行高效求解。
==尽可能使切分的每段分布差异最大化,使得分布的多样性尽可能大,从而增强模型学习后的泛化性能。==
这个操作类似聚类,但是不同的是聚类是点对点的度量,这里是对分布进行度量。
由于动态规划处理量过于庞大,使用贪婪算法
具体来说,高效计算和避免琐碎的解决方案,我们平均时间序列分割成𝑁个(N=10)部分,其中每一部分是最小单位时间内不能分裂了。然后随机搜索{2,3,5,7,10}中𝐾的值。给定𝐾,我们根据贪婪策略选择长度为𝑛𝑗的时间段。分别用𝐴和𝐵表示时间序列的起点和终点。我们首先考虑𝐾= 2,通过最大化分布距离𝑑(𝑆𝐴𝐶,𝑆𝐶𝐵),从9个候选拆分点中选取1个拆分点(记为𝐶)。确定𝐶后,我们考虑𝐾= 3,并使用相同的策略选择另一个点𝐷。类似的策略应用于𝐾的不同值。实验表明,该算法比随机分割算法能更好地选择合适的分割周期。
时序分布匹配TDM
基于以上切分的普通域泛化:
给定两个loss,一个是分类loss,一个是域差异D,使其尽可能最小化。
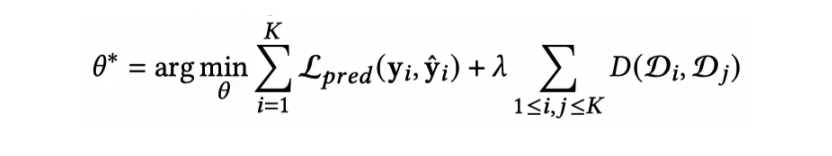
但是这样没有利用到RNN里每个 hidden state,所以本文提出了利用隐层的方法。
进一步利用RNN里每个hidden state的信息(更细粒度的域泛化):
RNN里每个hidden state对差异的贡献度不同,需要进行hidden state级细粒度的加权,筛选对分布差异最有影响的hidden state。
==将两个分布对齐,每个hidden state加入一个权重α(i,j,t三个变量来唯一标识一个α),在计算域差异损失的时候乘上对应的α==
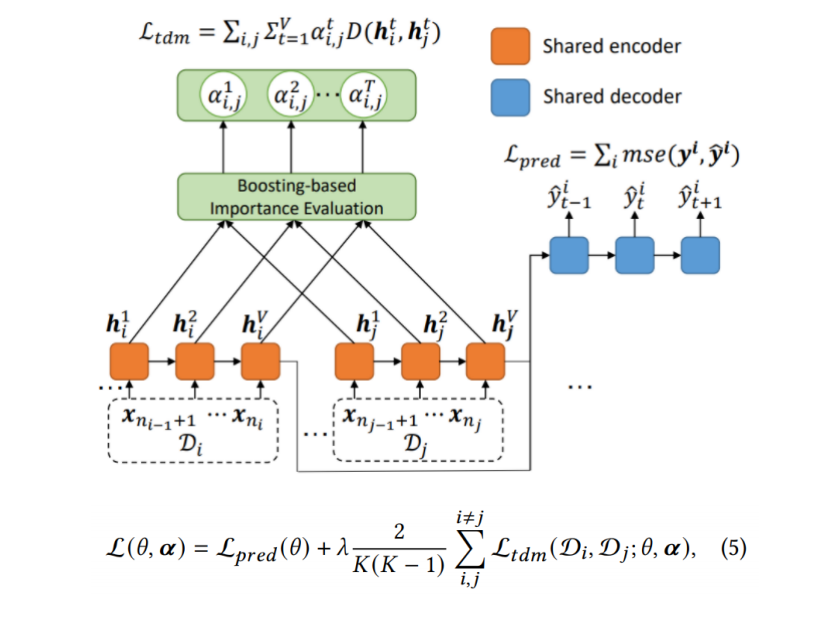
在所有分布上预训练获取更好的隐层表示
为了学习α学的更好
基于boosting的方式调节α
RNN同一层的α初始化为1/V (V是hidden state 个数)
哪个α要分的更大呢?当它对应的两个分布在该hidden state算出的距离比上一个hidden state大的时候,对a进行一个增加。否则不变。(选用距离来作为boosting的indicator)
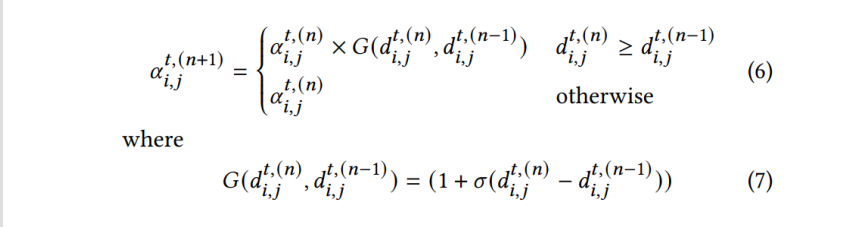
G是增加的系数的计算方式,计算一个大于1的数乘到当前α上。
实验
性能实验
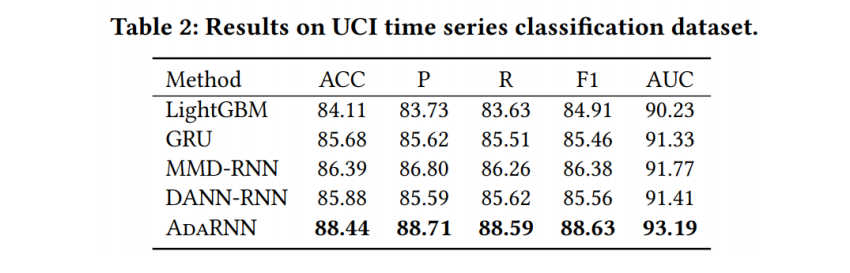
四个数据集上测试,一个分类任务,三个回归任务。
在人类活动识别、空气质量预测、家庭用电和财务分析方面的实验表明,AdaRNN在分类任务上的准确率比一些最先进的方法高出2.6%,在回归任务上的均方误差高出9.0%。
分类任务上(行为识别):
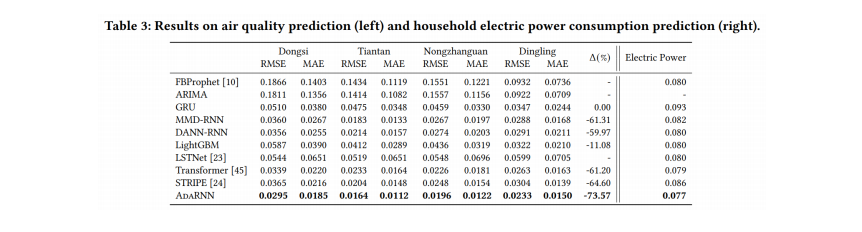
回归任务上:
(总共有3个,分别是空气质量预测、用电量预测和股价预测,下图给出的是空气质量预测)
分析性实验
做了非常多的实验,这里选几个重点说。
证明不同场景下最优的分割段数不同,并且本文提出的分割算法有效
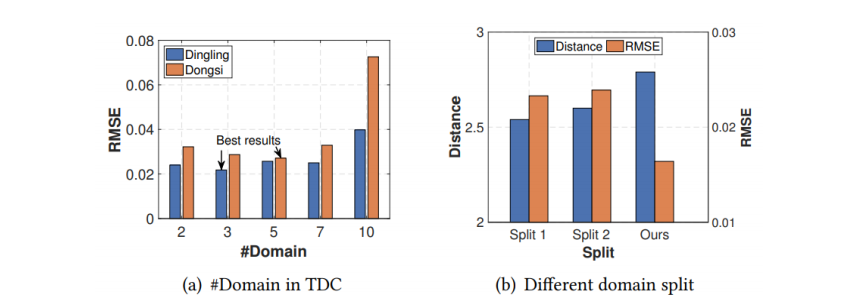
左:蓝色黄色两个场景下最适合的分割段分别为3和5,说明不同场景下最优的分割段数不同
右:第一个是随机分割,第二个是认为所有段概率分布相同,最后一个是用本文的分割算法,可以看到距离分出来是最大的(区域间差异性最强),并且最后的结果最优。
证明预训练和boosting方法有效,细粒度考虑hidden state是有必要的,并且本文方法与选用的距离计算函数无关

左图:证明预训练和boosting是有效的。(naive是非boosting的另一种方法,可以认为是没有α,不再详细介绍,文中的remark2部分有说。)
右图:体现有α可以使得选用的距离计算函数无关,并且α可以提升效果,说明在RNN里考虑每个hidden state的权重必要性。
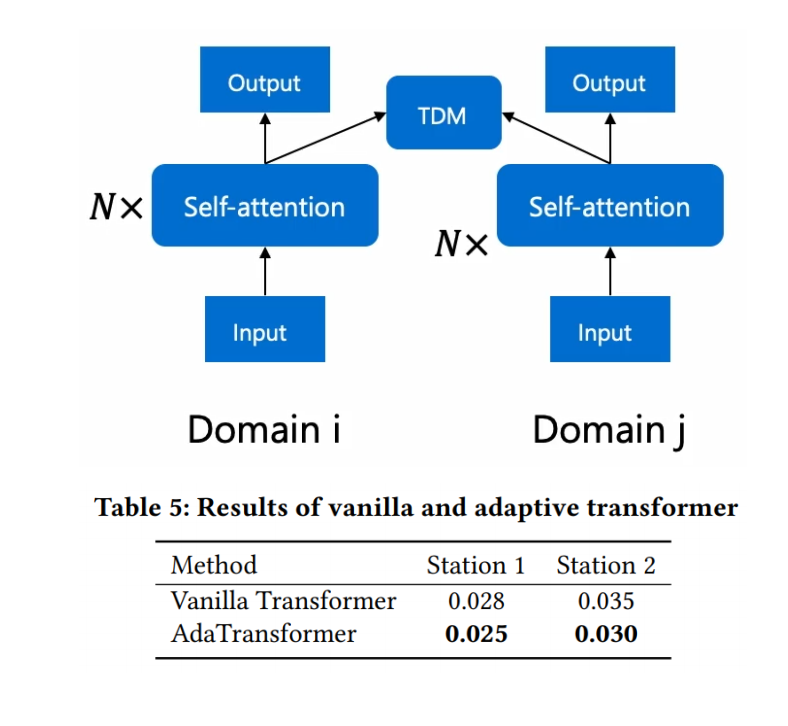
可扩展为transformer
我们还展示了时间分布匹配模块可以扩展到Transformer架构,以进一步提高其性能。
只做了简单的小实验,没有进行详细调参。
transformer也可以去做对齐。
总结
提出了一个基于分布变化的新颖问题(类似于跨session,但不是人工标记的session,是根据分布区分的,并且由算法自动寻找最优切分),并且采用了分布切分+减小差异两步方案解决这个问题。
这个工作可以被迁移和扩展。
比如第一阶段类似聚类的划分操作能不能有更好的深度学习方法实现。
或者后续工作可以直接套它第一阶段的贪心算法分割,对后面对齐的操作进行改进。
由于时序的连续性,本文强制采用了一种硬切分进行分割,边缘肯定存在难以区别的问题,或许可以提出一种软切分,让一个点可以归于两个或多个切分段
不太理解的
文中说:“现有的迁移方法均为基于卷积神经网络的分类问题而设计,也无法直接用于RNN模型。”是不是有点过了
后续问题
根据分布切分是否最好,比如睡眠里依据波形切分是否更好,用分布可能会把某些重要波形切掉,可能这种切分还是依据任务而定,当然用分布切分更通用。
协方差偏移的协方差确定是指x而不是某些变量间的吗。
补充材料
协变量偏移
源域和目标域的边缘概率分布是不同的,而条件概率分布是相同的
https://blog.csdn.net/qq_41076797/article/details/117153783
https://blog.csdn.net/mao_xiao_feng/article/details/54317852
会出现不符合机器学习假设训练集和测试集是独立同分布(I.I.D)的情况
模型漂移
模型漂移指的是旧的模型随着时间的改变,在最新特征下模型的效果会越来越差。模型漂移具体分为两类:concept drift和data drift。concept drift指的是label的分布或定义发生了变化,data drift表示特征的分布发生了变化。