关键词:大规模,异常检测

摘要:数据挖掘和时间序列计算在关键应用中仍值得研究。目前,在水文时间序列领域,大部分异常值的检测都集中在提高特异性上。为了有效检测海量水文传感器数据中的异常值,提出了一种基于Flink的水文时间序列异常检测方法。首先,利用滑动窗口和ARIMA模型对数据流进行预测。然后对预测结果计算置信区间,区间范围外的结果判断为备选异常数据。最后,基于历史批次数据,使用KMeans++算法对批次数据进行聚类。计算状态转移概率,对异常数据进行质量评估。以从楚江获取的水文传感器数据为实验数据,分别进行了检测时间和异常检测性能的实验。结果表明,在计算数千万个数据时,两个从机花费的时间比一个从机少,最大减少量为17.43%。评价的灵敏度从72.91%提高到92.98%。延迟方面,不同从机的平均延迟大致相同,维持在20ms以内。结果表明,在大数据平台下,该算法能有效提高数千万数据的水文时间序列检测的计算效率,并给出可靠的置信度,以提高整体灵敏度(不漏报)。在大量的水文时间序列中可以快速,准确地检测到异常值。
介绍
水文数据根据其物理量分为各种类型的水文时间序列。目前,水文时间序列通常由确定的和随机的成分组成。确定成分具有一定的物理概念,而随机成分是由不规则振荡和随机影响产生的。水文时间序列主要表现出随机性,模糊性,非线性,非平稳性和多时间尺度变化的复杂特征。
随着世界变得更加硬件化和互联,我们看到了各种硬件(例如传感器)或软件生成的大量数字数据。随着信息化的发展,水文站积累了大量重要数据,其中包含许多异常值。异常值通常包含重要信息,通过准确地找到数据背后的隐含价值,这对于后续的分析决策非常重要。目前,对于水文时间序列,传统方法仅适用于小型数据集,不适用于当前的大数据环境。而且,准确度虽达到99%的特异性(Specificity,不误报,TPR = TP / (TP + FN) ),灵敏度(Sensitivity,不漏报,召回率、查全率,TNR = TN / (TN + FP) )仍然有提高的空间。随着数据量的增加,如何有效地进行计算已成为不可忽视的问题。在关键应用中时间序列的异常检测和计算仍然值得研究。
Apache Flink
Flink 是一套集高吞吐、低延迟、有状态三者于一身的分布式流式数据处理框架。
具体来说,Flink 是一个解决实时数据处理的计算框架,其可对有限数据流和无限数据流进行有状态计算,并能部署在各种集群环境,对各种大小的数据规模进行快速计算。
Flink 支持消息队列的 Events(支持实时的事件)的输入(如Kafka),上游源源不断产生数据放入消息队列,Flink 不断消费、处理消息队列中的数据,处理完成之后数据写入下游系统,这个过程是不断持续的进行。
层次化的API在表达能力和易用性方面各有权衡。表达能力由强到弱(易用性由弱到强)依次是:ProcessFunction、DataStream API、SQL/Table API。
时间序列异常检测中,Flink具备批流一体(离线训练和在线训练同一套框架)、性能优异、并行计算等优势。针对不同的使用场景,分为基于时序预测和时序分解两种类型:
时序预测算法适合流式数据,即时响应
时序分解算法适合全量数据,能够从全量数据中挖掘有效信息。
滑动窗口
滑动窗口就是能够根据指定的单位长度来框住时间序列,从而计算框内的统计指标(均值、方差、标准差中位数、和等)。相当于一个长度指定的滑块正在刻度尺上面滑动,每滑动一个单位即可计算滑块内的数据。
Flink为我们提供了方便易用的窗口算子API,我们可以将数据流切分成一个个窗口,对窗口内的数据进行实时处理。窗口的大小设置导致延迟的大小变化。(窗口越大延迟越高)
ARIMA模型
时间序列的平稳性:由时间序列所得到的拟合曲线在未来一段时间内仍能顺着现有的形态惯性地延续下去。平稳性要求序列的均值和方差不发生明显变化。
AR:自回归模型,描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。
自回归模型的限制:
1、自回归模型只能用自身的数据进行预测
2、时间序列数据必须具有平稳性
3、自回归只适用于预测与自身前期相关的现象(泛化不足)
I:差分法,可以使得数据更平稳,常用的方法就是一阶差分法和二阶差分法。
MA:移动平均模型,移动平均模型关注的是自回归模型中的误差项的累加,能有效地消除预测中的随机波动。
ARIMA(p,d,q):差分自回归移动平均模型,将自回归模型、差分法和移动平均模型结合以来
p是自回归(AR)的项数,用来获取自变量
d是差分(I)的系数,为了使时间序列平稳,做d次差分
q是移动平均(MA)的项数,为了使其光滑
ARIMA原理:将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的当前值和滞后值进行回归所建立的模型
建立ARIMA模型的流程:
1.确定参数p,q 的值
2.确定d阶
3.计算AIC或BIC,原则是使AIC和BIC越小越好
置信区间
置信区间是总体变量估计的界限,它是一个区间统计量,用于量化估计的不确定性。在应用机器学习中,我们想在展示一个预测模型的能力时使用置信区间。选择95%的置信度在展现置信区间时很常见。实践中,你可以使用任何喜欢的值。置信区间的价值在于它能够量化估计的不确定性。它提供了一个下限和上限以及一个可能性。
KMeans++算法
K-means与K-means++:原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。在选取第一个聚类中心(n=1)时同样通过随机的方法。可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。


转移概率矩阵
转移概率矩阵:矩阵各元素都是非负的,并且各行元素之和等于1,各元素用概率表示,在一定条件下是互相转移的,故称为转移概率矩阵。
马尔可夫链
马尔可夫性:过程或(系统)在时刻t0所处的状态为已知的条件下,过程在时刻t > t0所处状态的条件分布,与过程在时刻t0之前所处的状态无关的特性称为马尔可夫性
马尔可夫过程:具有马尔可夫性的随机过程称为马尔可夫过程。
马尔可夫链:时间和状态都是离散的马尔可夫过程称为马尔可夫链,主要用于分析随机事件未来发展变化的趋势。
基于Flink的水文时间序列异常检测算法
由于该实验的时间格式,水平标记重叠并且观察效果差。因此,将天数用作水平轴。然后,我们引入时间连续的数据流以进行异常检测。
以下是原始水文时间序列的一部分。

一、数据预处理
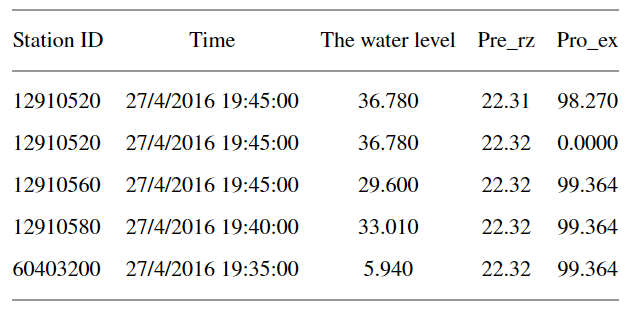
在进行异常检测之前,应先清理获取的数据,清理前的数据如下。
原始数据集中存在很多问题,例如重复,排序混乱,日期格式不符合数据挖掘要求以及不相关序列的存在。为解决上述问题,我们基于Flink处理了18910864行水文数据,消除其中的无效数据和重复数据,并统一了数据格式。
二、异常检测
(1)本篇论文的ARIMA模型参数如何确定的?
答:我们通过对时间序列进行单位根检验,判断出是非平稳序列,再通过差分将其转换为平稳序列。最后根据AIC准则,我们确定了自回归阶数p和移动平均阶数q,并找到具有最小AIC值的p和q组合
(2)ARIMA模型预测的是单点预测还是多点预测?
答:是多点预测,通过将初始时间序列由滑动窗口划分为一段段的序列,再由窗口滑动时,将窗口内的原始数据值输入到ARIMA模型形成一个新的时间序列

首先,时间序列的ARIMA模型{x1,x2,…,xn}通过滑动窗口的预测检验(Forecast Testing)思想建立了“预测值”,并获得了预测检验的置信区间,并将其与原始数据进行比较得出候选异常值。该算法使用滑动窗口和ARIMA模型在Flink平台上进行预测。
以下是设置了滑动窗口长度为6的数据集上使用ARIMA模型检测到异常的情况下,显示出置信度为95%的测量值和置信区间。由图可知,大多数点都非常接近正常值,但是在区间外还有一些点,因此它们被判断为可疑异常点。

三、结果验证
为什么要通过聚类再使用马尔可夫链的状态转换矩阵来计算其真实异常值的概率?
答:K-Means++算法模型训练完成后,可以得到离散的状态序列{T1,T2,…},并且通过将矩阵转换为数据帧计算获得状态转移矩阵。再将ARIMA模型得到的可疑异常点集及其前一时刻的值输入到聚类训练好的模型中,以获取异常状态及其前一时刻状态,再通过状态转换数据帧估计异常的值及其前一时刻的值,输出真实异常值的概率。
马尔可夫过程中的状态转移矩阵有什么意义?
答:马尔可夫每个时间点处在某一个状态,时间是离散的,每次到下一个时间点时按照图进行随机状态转移。假如某时的状态是个统计分布(看做向量),那么用状态转移矩阵(图里头边的权值)乘这个向量就得下一时刻的状态。不管初始状态是什么概率分布,状态转移矩阵不断乘它,这个状态向量最终会达到某个确定的平衡点。
解释链接:https://www.zhihu.com/question/41423304?sort=created
在检测到异常值之后,通过K-Means++算法对原始数据进行聚类,并在聚类后使用状态转换矩阵来计算其真实异常值的概率。最后通过状态转移评估异常值并最终确定异常值。
在表中,t0表示传输前的状态,t1表示传输后的状态。通过对初始水文时间序列进行聚类,选取异常值的状态和它们的前一阶矩,并在表3中查找得到真实异常值的概率,得到了以下结果。
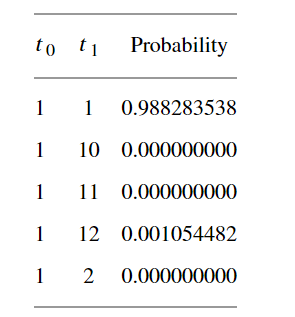
2.表中显示预测检验部分检测到的值确实是异常值的概率,可以看出某些检测值的真实异常值的概率为0,所以我们将这些真实异常值的概率小于50%的值从检测值中剔除。最终检测出水文时间序
列中的异常值。
实验结果
实验环境和数据集
运行时环境在使用四台PC的群集中部署,相关软件版本如下:Java 1.8和Flink 1.5.2,数据集为18910864行记录。
如果基于滑动窗口来预测时间序列,则会出现高延迟和长时间运行的计算时间。采用Flink进行计算,比较了在不同计算资源下使用Flink执行算法的时间。结果如下。
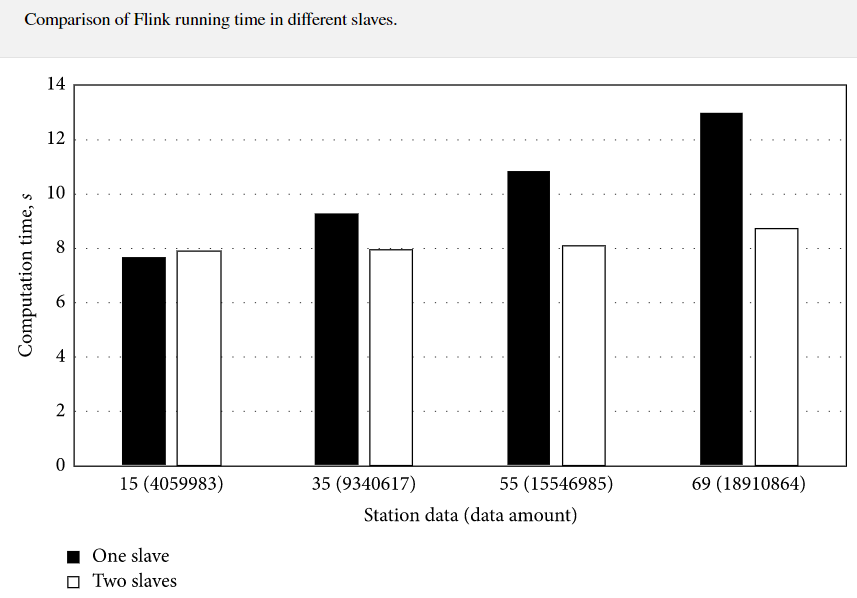
从图中可以看出,在选择15个和35个水文站的数据的情况下,双节点的运行速度并不理想,但是当数据量增加到数千万级时,双节点的优势可以体现出计算时间的优势。可以看出,在较大的数据集下,计算速度更快。
有效性和准确性
检测到的异常值,并使用状态转换矩阵来计算其真实异常值的概率。为了验证该机制的有效性和准确性,将实验结果分为四类。第一类为TP(真阳性),判断为实际异常。第二类为FN(假阴性),实际异常被判断为正常;第三类为FP(假阳性),判断为实际正常。最后一个类别是TN(真负),并且实际法线被判断为法线。TP和TN是不需要FN和FP的理想情况。本文定义了灵敏度Sensitivity=TN / (TN + FP) 以及特异性,Specificity=TP / (TP + FN)。本文将基于滑动窗口,MARS的ARIMA模型和本文的算法在相同的水文时间序列数据集上进行了比较,结果如下
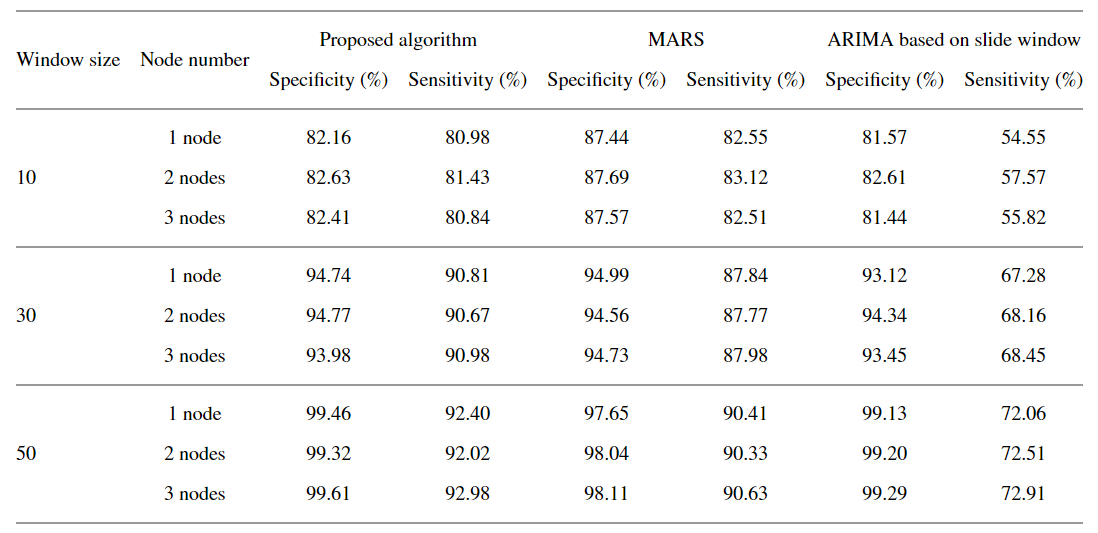
表中显示了三种模型的最佳结果进行比较。结果表明,传统的窗口方法在特异性方面(不误报)与本文提出的方法没有显着差异,保持了较高的准确性。在灵敏度(不漏报)方面,作为一种非线性预测模型,MARS在样本较小的情况下表现较好,最高达到83.12%。但是,随着窗口大小的增加,这种增加不如本文提出的算法好,因为本文的算法包含了历史校验机制,使用历史数据对实时数据进行校验。随着窗口大小的增加,本文提出的算法与传统算法相比有了明显的提高,灵敏度从72.91%提高到92.98%。与MARS模型相比,改进幅度高达2.75%。
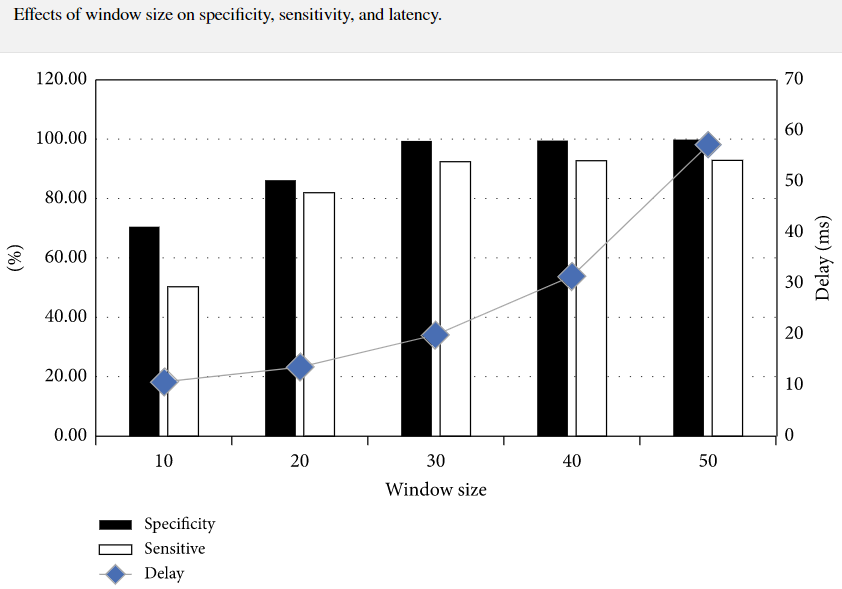
从图中可以看出,随着窗口数量的增加,当窗口大小约为30时,特异性和灵敏度迅速提高。在窗口大小从10增大到30的过程中,特异性提高了29.47%,达到99.47% ,灵敏度增加了42.08%,达到了92.44%,而延迟增加了93.32%,达到了19.92 ms。但是,当窗口大小大于30时,特异性和灵敏度变化不大,但延迟率增加到57.21 ms,增加了187.2%。因此,理想的选择是将窗口长度设置为大约30,这可以使平均延迟小于20 ms。
总结
在大数据时代,传统的检测算法无法满足当前的需求。针对滑窗的特点以及传统滑窗检查的时间复杂度高,检错率高等缺点,提出了一种基于Flink的水文时间序列异常检测方法。通过使用Flink计算,此方法减少了计算时间,并将两个过程结合在一起。
以楚河水文传感器的数据为实验数据,分别对离群值的检测时间和有效性进行了实验。结果表明,使用2个从站的百万个数据在计算时间上要比1个从站花费更多的时间,但是当计算十个数据时,2个从站比1个从站要好,最大值减少了17.43%。评估的灵敏性从72.91%增加到92.98%。在延迟方面,不同从站的平均延迟大致相同,保持在20 ms以内。结果表明,当该方法用于检测数以千万计的水文数据时,通过添加节点可以有效地提高Flink的计算效率。同时,与传统方法相比,该方法的灵敏度大大提高。